Three Claude skills for end-to-end Ghost blog publishing
Three composable Claude skills that handle Ghost blog publishing end to end: topic research, HTML draft, schema injection, and Admin API POST - with the gotchas encoded.

TL;DR: Install three free Claude skills - blog-topic-research, ghost-blog-writer, and blog-figure-svg - to automate Ghost blog publishing from topic vetting to a live, schema-annotated post, all in one agent session.
Ghost's Admin API is clean and well-documented - until you hit the parts that aren't. Lexical silently strips <script> tags from body HTML, taking your JSON-LD schema with it. feature_image_alt has a 191-character hard cap with no visible error on save. Tags must be objects, not strings. The three skills in the publishing-skills bundle encode these constraints and handle the full post lifecycle as composable Claude skill files.
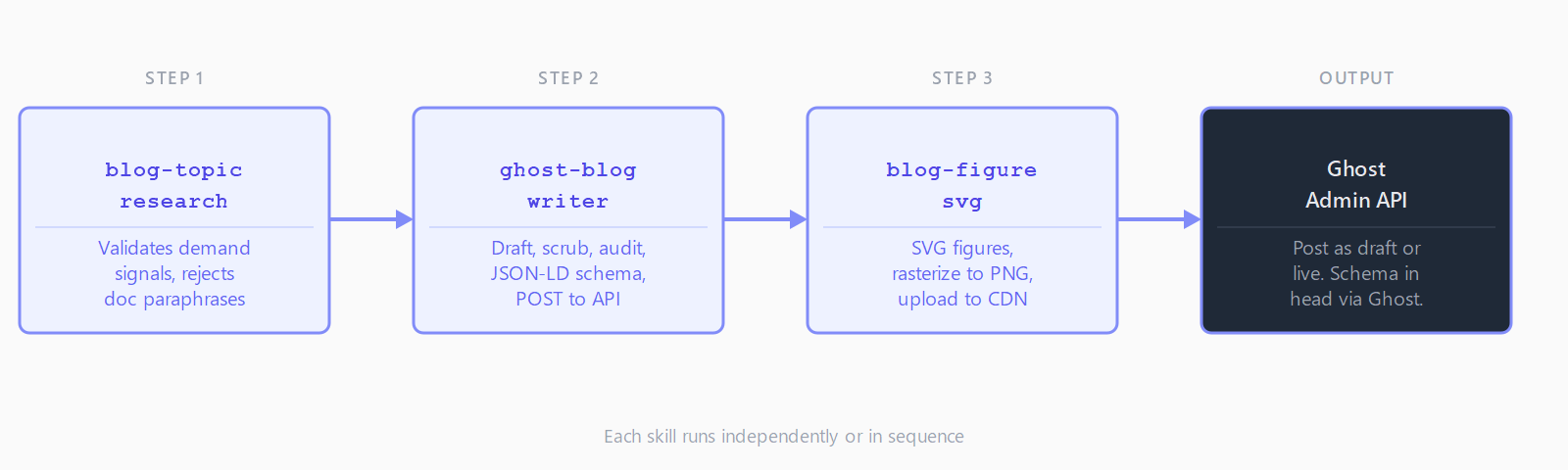
What does each of the three publishing skills do?
blog-topic-research runs WebSearch and WebFetch against a proposed topic, collects demand signals - Reddit threads, GitHub issues, People Also Ask boxes, Stack Overflow questions - and refuses to continue if the result would just reword vendor docs. Output is a structured research scaffold the writer skill reads directly.
ghost-blog-writer takes a topic (or the research scaffold) and runs an end-to-end pipeline: draft in HTML, character scrub for LLM tells (em-dashes, smart quotes, "delve into"), AI-SEO audit, FAQPage and BreadcrumbList JSON-LD block generation, payload validation, and POST to the Ghost Admin API with ?source=html. The local validator catches the 191-char alt text cap and tag-format rules before the API call, so debugging happens locally rather than in a 422 response body.
blog-figure-svg generates accessible SVG figures - flow diagrams, comparison bar charts, taxonomy diagrams, annotated terminal mocks - with a system-font palette and role="img" plus <title> and <desc> metadata for screen readers. It rasterizes to PNG, uploads to Ghost's CDN, and splices the <figure> tag into the draft. One figure per ~500 body words is the rule.
How do you install the publishing skills?
Two paths, same files. Via clawhub:
npm i -g clawhub
clawhub login
clawhub skill install blog-topic-research
clawhub skill install ghost-blog-writer
clawhub skill install blog-figure-svgOr via git clone from the publishing-skills repo:
git clone https://github.com/ratamaha-git/publishing-skills.git
cp -r publishing-skills/skills/* .claude/skills/After installing, restart your agent host. Claude Code is the primary target runtime; for Windows-specific env var configuration, the Claude Code MCP setup guide covers the same pattern. No build step and no npm dependencies for the skill files themselves.
For ghost-blog-writer, set two env vars: GHOST_URL (your Ghost root URL) and GHOST_ADMIN_KEY_SECRET from Ghost Admin > Settings > Integrations, in id:secret format. The research skill uses your agent's built-in WebSearch and WebFetch - no extra credentials. The figure skill needs ImageMagick, rsvg-convert, Inkscape, or cairosvg for PNG rasterization.
What does Ghost silently break in the publish flow?
Three constraints that cost a debug session if you hit them blind:
Lexical strips <script> from body HTML. Ghost converts source HTML to Lexical rich-text on save and removes <script> nodes in the process. If you inline JSON-LD schema in the draft body, it appears in the POST payload but disappears from the live post. The correct location is the codeinjection_head field - Ghost renders it verbatim into <head> via {{ghost_head}} and Lexical never touches it.
feature_image_alt is varchar(191). Ghost's posts table stores the alt text in a 191-character column. Exceeding it returns a 422. The skill's payload validator asserts len(alt) <= 191 before every POST.
Tags must be objects, not strings. A tag payload of ["n8n", "How To"] creates orphaned duplicate tags in Ghost on each publish. The correct form is [{"name": "n8n"}, {"name": "How To"}]. The skill validates against a canonical allowlist before building the payload.

What does a publishing run look like in practice?
With the skills installed and credentials set:
- Run
/blog-topic-research <topic>. The skill collects demand signals, checks for doc-paraphrase risk, and writes a research scaffold totmp/blog-drafts/<slug>.research.md. - Run
/ghost-blog-writer <topic>. The skill reads the scaffold, drafts in HTML, scrubs LLM tells, invokesblog-figure-svgfor illustrations, builds JSON-LD intocodeinjection_head, and POSTs to Ghost as a draft by default. Add--publishto go live directly. - Review the post in Ghost admin. Schema, feature image, and tags are already wired. Approve and publish.
The skills are also useful independently. Run ghost-blog-writer alone with a topic you're confident in, skipping the research preflight. Run blog-topic-research to vet an editorial backlog before committing to drafts. Run blog-figure-svg for any Ghost post that needs a chart, regardless of how the prose was written.
This is the pipeline automatelab.tech runs for all its posts. The product page at automatelab.tech/products/publishing-skills/ links to each skill's clawhub page and the public GitHub repo.
FAQ
Do the skills work with any Ghost blog, not just automatelab.tech?
Yes. The automatelab-specific parts - tag taxonomy, author slug, editorial backlog - are parameterized. Point GHOST_URL at any Ghost instance and set your own tag names and author slug. The API calls and gotcha handling are generic across Ghost versions.
Can ghost-blog-writer run without the other two skills?
Yes. It runs standalone with a topic you supply directly. The research preflight is optional; the figure skill is invoked during the illustration pass but can be skipped. Use all three for the full pipeline, or one at a time when that is all you need.
Why does Ghost strip my JSON-LD from the post body?
Ghost's Lexical editor removes <script> tags from body HTML on conversion. Put JSON-LD in the post's codeinjection_head API field instead - it renders directly into <head> and bypasses Lexical sanitization entirely.
Which agent runtimes do these skills support?
Any runtime that supports SKILL.md and YAML frontmatter: Claude Code, Claude Desktop, Cursor, Cline, and most harnesses that have adopted the format. The skills do not require the Model Context Protocol - they are prompt scaffolds with optional Python helpers, so they work in runtimes without MCP support.
What does the publishing pipeline cost to run?
The skills are MIT-0 licensed and free. You pay for your agent's model usage (Claude Sonnet or Opus for the writer, Haiku for research) and your Ghost hosting. A complete post - research, draft, figures, publish - typically uses $0.10-0.30 in model tokens depending on length and figure count.
The orchestration layer is the agency-os planning board - a Notion workspace that tracks every post from idea to live URL.
If you also want the on-page AI-SEO layer — FAQPage schema, llms.txt, entity links, AI-crawler access — implemented for your site, see the AI SEO service.