Launching content-distribution-mcp: one finished post, eight channels
One finished post fans out to DEV.to, Hashnode, GitHub Discussions, Bluesky, Reddit, Medium, LinkedIn, and Twitter from any MCP host.

TL;DR: Publishing one post to eight developer-community channels is a full day of work — every channel has its own character limits, tag vocabulary, canonical-URL rules, formatting quirks, and anti-spam gates. content-distribution-mcp turns that into a 15-minute agent run: one finished post, eight per-channel variants shaped to each platform's constraints, idempotent state so retries never double-post, and LinkedIn via OAuth 2.0 Posts API. Wire it into any MCP host (Claude Code, Cursor, n8n, plain Python). YAML or Notion backend.
Why is cross-posting one article to eight channels so painful?
The visible work in cross-posting is clicking Submit eight times. The actual work is everything that has to happen before Submit, and it is different on every channel:
- Format and length. DEV.to and Hashnode want long-form Markdown with front-matter and a canonical URL field. Bluesky caps at 300 graphemes and has no canonical field, so the link goes in the post body. GitHub Discussions accepts Markdown but has no canonical field either, so you append a footer. LinkedIn wants plain text with hand-spaced line breaks because it strips Markdown. Twitter wants a thread.
- Tag and category vocabularies. DEV.to allows up to four tags from a curated list. Hashnode wants its own tag slugs. Reddit wants a flair that varies per subreddit. Get any of these wrong and the post gets rejected or buried.
- Anti-spam and community rules. Each subreddit has its own cooldown, self-promotion ratio, and required flair. Post twice in two hours and Automoderator nukes you. Medium's compose form needs hand-pasting because there is no public write API. Twitter's free tier is unusable for posting.
- Idempotency and retries. A network blip between "Hashnode returned 200" and "we wrote the state row" produces a duplicate article on the next retry. Doing this by hand means you also remember what you already posted, where.
So a single release becomes: rewrite the same idea eight ways, look up each channel's rules, paste into eight composers, track what went live, and pray no retry creates a duplicate. That is a day of work for one post. Multiply by a publishing cadence and it is the reason most indie devs stop cross-posting after week three.
How does an MCP-based agent solve cross-posting?
content-distribution-mcp is the open-source Model Context Protocol server that collapses that day into one agent run. The agent reads the source post, queries the MCP's hints() tool for each channel's constraints (char limits, tag vocabulary, canonical-URL support, footer rules), generates eight per-channel variants that respect those constraints, and calls publish(). The MCP handles auth, idempotency, scheduling, retries, and the Reddit anti-spam pre-flight. Auto-tier channels go out in seconds; manual-tier channels (Reddit, Medium, Twitter) get a plain-text draft and a pre-filled compose URL so the human click is fifteen seconds, not fifteen minutes.
Total wall-clock time on our last release: about 15 minutes, most of it spent reviewing the generated variants before approving the publish. We shipped the server on npm and GitHub today.
Why did we build content-distribution-mcp?
We publish the same post across DEV.to, Hashnode, GitHub Discussions, Bluesky, Reddit, Medium, LinkedIn, and Twitter. The first version of that pipeline was a Python script. The second was an n8n graph. Both broke in the same three places: a network blip created a duplicate, a Reddit submission got removed by Automoderator because the account had posted to the same subreddit two hours earlier, and the credentials lived in three places at once. Underneath all of that, the per-channel adaptation work — eight different rulebooks for the same idea — was still being done by hand every release.
We also wanted the publishing step to be callable from whatever harness we used at the time. Today that is Claude Code; six months ago it was a plain Python loop; tomorrow it will probably be something else. MCP is the protocol that lets a tool stay portable across those hosts, so we wrote the distribution server against it from the start. The sibling pieces in our stack, the n8n MCP server and the AI-SEO MCP, follow the same rule.
What is content-distribution-mcp?
A model-agnostic MCP server that takes a finished piece of content and routes it to developer-community platforms with idempotent state management and dual Notion or YAML backends.
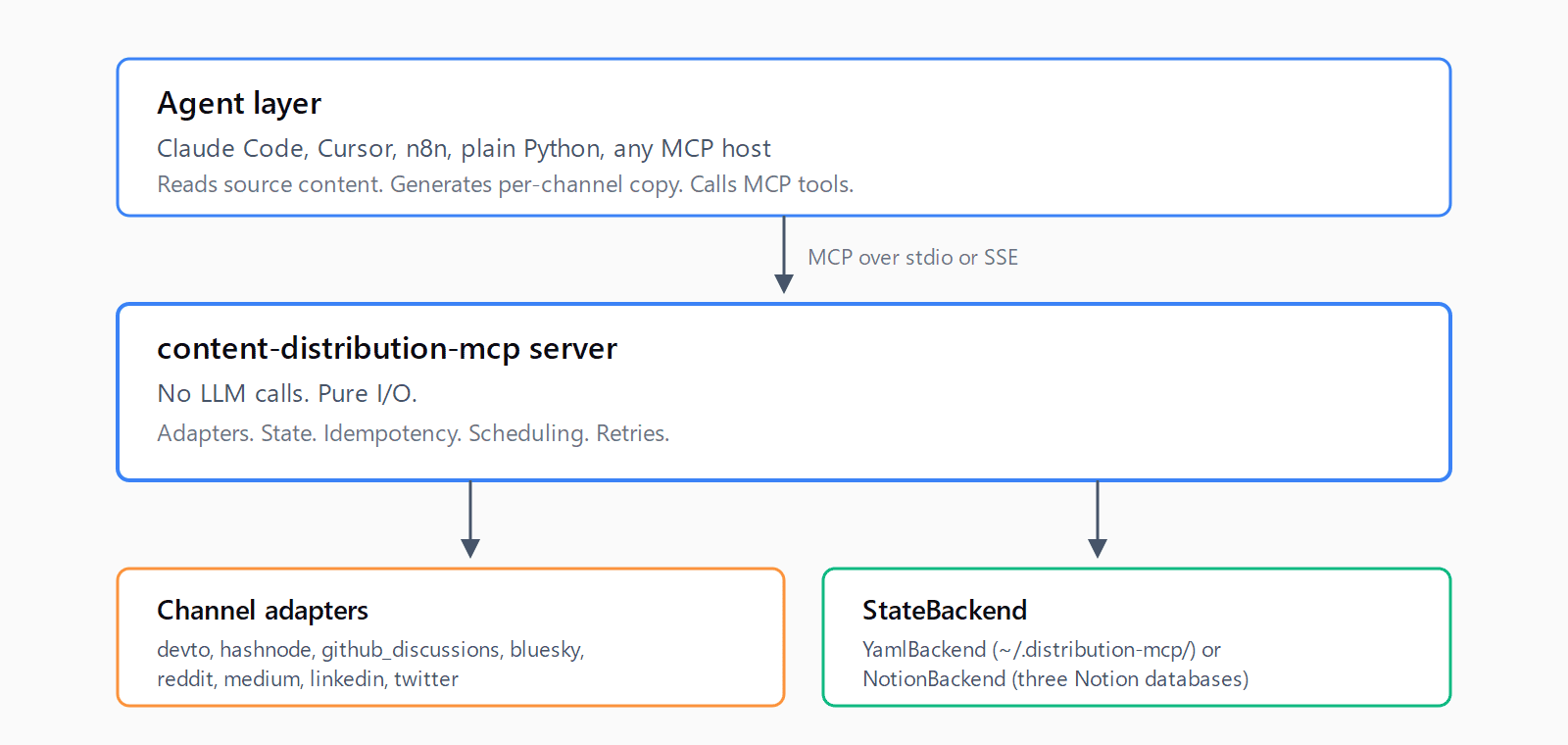
The server makes no LLM calls of any kind. There is no anthropic import anywhere in src/. All copy transformation is the caller's responsibility; the MCP hands back per-channel constraints via the hints() tool and the agent decides what to do with them. That is what "model-agnostic" actually means here, not a marketing label.
It runs unchanged under Claude Code, Claude Desktop, Cursor, n8n via the MCP Client node, and plain Python with the mcp client library. Anything that speaks MCP over stdio or SSE works. The host process supplies credentials and host-generated Variant text; the MCP supplies idempotent I/O.
Architecturally there are three layers. The agent layer reads source content, generates per-channel copy (the LLM work lives there), and calls MCP tools. The MCP server layer is pure I/O with no LLM calls: adapters, state, idempotency, scheduling, retries. The backend layer stores Distribution Profiles, the Subreddit Catalog, the Post Log, and the Scheduled Queue. The boundary matters because it is what keeps the server useful when you swap models or change harnesses.
Which tools does content-distribution-mcp expose?
Eight tools, each with a single job. Full docstrings live in spec.md.
| Tool | Purpose |
|---|---|
publish | Immediate publish; idempotent on (content.id, variant.channel) |
schedule | Queue variants for a schedule_at timestamp |
drain | Fire any due scheduled posts (cron-friendly, one-shot) |
status | Per-variant state for a content piece |
unpublish | Best-effort delete (DEV.to and GitHub Discussions only) |
hints | Static per-channel metadata: char limits, tag vocabulary, canonical-URL support |
list_profiles | Configured Distribution Profiles |
list_subreddits | Curated Subreddit Catalog entries |
The load-bearing detail is idempotency. Every publish call keys on (content.id, variant.channel). If the network drops between "Hashnode returned 200" and "we wrote the state row", a retry sees the existing successful state and returns the same URL instead of posting a second article. The state lives in whichever backend you wired in, which is the next section.
schedule queues a variant with a schedule_at timestamp. drain is the cron-friendly one-shot that fires anything due and exits, so you can run it from a system cron or a GitHub Action without keeping a long-lived process alive. hints returns static per-channel metadata so the agent can shape copy correctly: DEV.to accepts up to four tags from a curated vocabulary; Bluesky posts cap at 300 graphemes; GitHub Discussions does not have a canonical-URL field and needs a footer instead. None of that lives in the agent's prompt; it lives in the MCP and gets queried on demand.
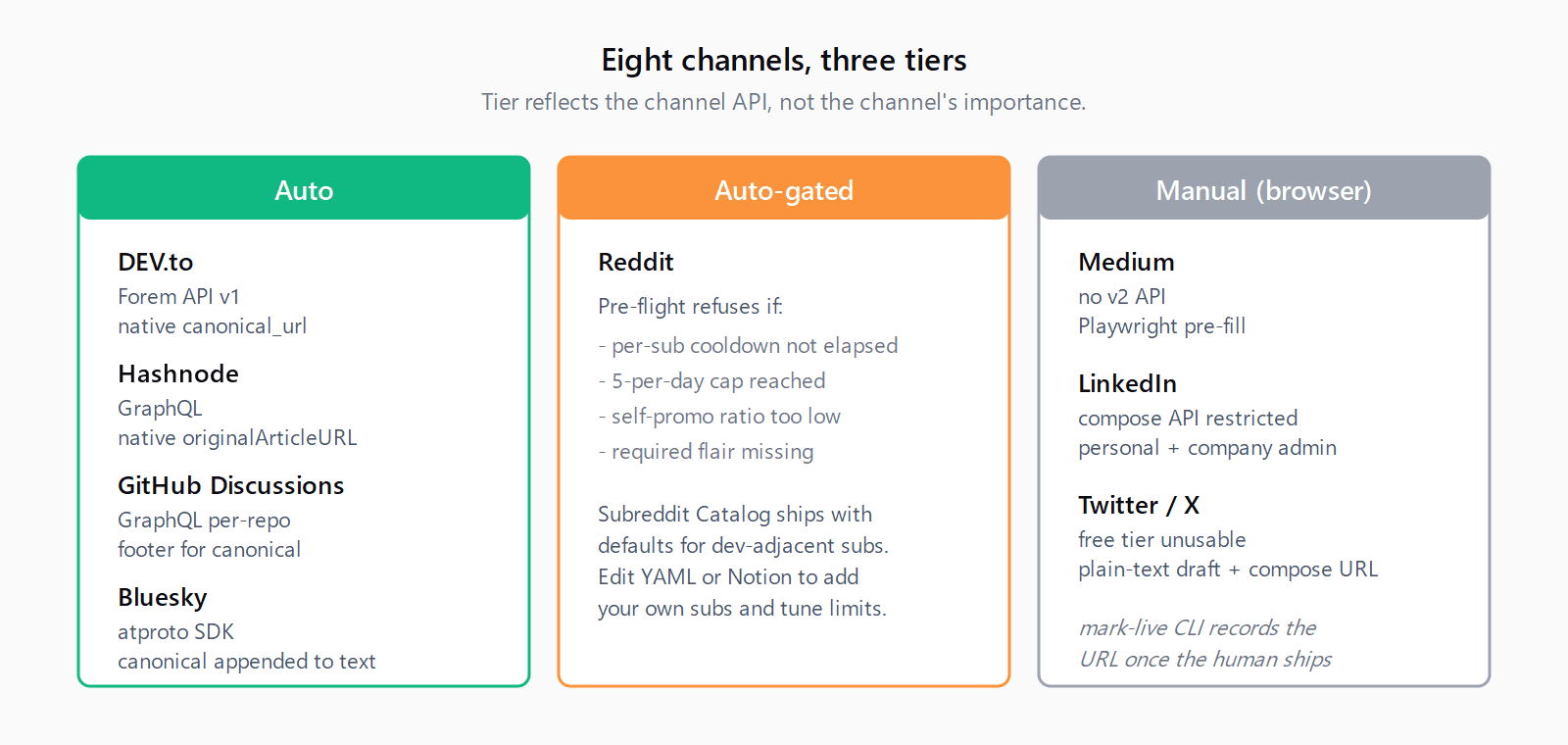
Which channels does content-distribution-mcp support?
| Channel | Tier | Notes |
|---|---|---|
| DEV.to | Auto | Forem API v1, native canonical_url |
| Hashnode | Auto | GraphQL, native originalArticleURL |
| GitHub Discussions | Auto | GraphQL per-repo, footer for canonical (no native field) |
| Bluesky | Auto | atproto SDK, canonical link appended to post text |
| Manual (browser) | Plain-text draft plus pre-filled submit URL, mark-live CLI. No credentials needed. | |
| Medium | Manual (browser) | Plain-text draft plus compose URL, mark-live CLI |
| Auto | OAuth 2.0 Posts API. Run linkedin install once to provision the token. | |
| Twitter / X | Manual (browser) | Free-tier API unusable; plain-text draft and compose URL, mark-live CLI |
The "manual (browser)" tier is for hostile or dead APIs. Medium has no public write API. Twitter's free tier is effectively unusable for posting. Reddit's API has unpredictable rate limits. For those three, the adapter writes a plain-text draft to disk, returns the compose URL, and records state="needs_browser" in state. The operator pastes the draft into the compose form and clicks Submit. The mark-live CLI then records the live URL back into state, so status() still returns the truth.
Should you use YAML or Notion as the backend?
State lives in a backend that implements the StateBackend protocol. Two ship in the box.
YamlBackend stores four YAML files in ~/.distribution-mcp/: Distribution Profiles, Subreddit Catalog, Post Log, and Scheduled Queue. Zero config, right for solo and local use. git init the directory and version it.
NotionBackend stores the same shape across three Notion databases (Distribution Profiles, Subreddit Catalog, Post Log), with URL write-back to the source task on success. Right for team and agency use. The provisioner builds the three databases for you:
content-distribution-mcp provision-notionThe MCP picks the backend from a constructor argument. Caller code does not change when you swap them, which means you can prototype on YAML on your laptop and move the same workflow into a Notion-based agency board later without rewriting anything.
How do you install content-distribution-mcp?
Requires Node.js 18 or later. The server is published on npm as @automatelab/content-distribution-mcp and runs via npx with no global install required.
npx -y @automatelab/content-distribution-mcp serveWire it into your MCP host. For Claude Code, drop this into .claude/mcp.json:
{
"mcpServers": {
"content-distribution": {
"command": "npx",
"args": ["-y", "@automatelab/content-distribution-mcp", "serve"]
}
}
}For n8n, install the MCP Client node and point it at the same npx command over stdio. Any host that speaks MCP works the same way. The repo README has runnable examples for every host.
How do we use content-distribution-mcp at AutomateLab?
This post published itself through the server we are announcing. The Ghost draft was written by a Claude Code skill, the five auto-tier variants (DEV.to, Hashnode, GitHub Discussions, Bluesky, LinkedIn) were routed to their respective APIs automatically, and the manual-tier variants (Reddit, Medium, Twitter) sit behind the browser adapter waiting for a human click. State is in the YAML backend in ~/.distribution-mcp/; we will move it to Notion when the team grows past one person.
Links
- Product page: automatelab.tech/products/mcp/content-distribution-mcp/
- npm: @automatelab/content-distribution-mcp
- GitHub: AutomateLab-tech/content-distribution-mcp
FAQ
What is content-distribution-mcp?
An open-source MCP server that publishes one piece of content to eight developer-community channels: DEV.to, Hashnode, GitHub Discussions, Bluesky, Reddit, LinkedIn, Medium, and Twitter. Idempotent on (content.id, variant.channel), with per-subreddit anti-spam pre-flight and dual YAML or Notion backends. MIT-licensed.
How is this different from Buffer or Hootsuite?
Two things Buffer and Hootsuite do not do: an idempotency key that survives retries so a network blip never produces two posts, and LinkedIn publishing via OAuth 2.0 Posts API so it fires automatically alongside the rest of your channels. It is also a tool, not a SaaS; you run the server yourself and the state lives on disk or in your Notion workspace.
Does it work with non-Claude MCP hosts?
Yes. The server has zero Anthropic-specific code. It speaks standard MCP over stdio or SSE and works unchanged with Cursor, Claude Desktop, Claude Code, n8n via the MCP Client node, and any LLM SDK (OpenAI, Anthropic, Gemini, Ollama, or none at all). Run grep -ri "anthropic" src/ to verify.
How do I install it?
Node.js 18 or later: npx -y @automatelab/content-distribution-mcp serve. No global install required. For LinkedIn, run npx -y @automatelab/content-distribution-mcp linkedin install once to provision the OAuth token. Then wire the same npx command into your host's MCP config.
What does it cost?
The server is free under the MIT license. You pay for whatever the channels charge: DEV.to, Hashnode, GitHub Discussions, Bluesky, and Reddit are free; Medium, LinkedIn, and Twitter post via your existing accounts. There are no hosted fees, no per-post metering, and no LLM tokens consumed by the server itself.