How to work around Make's 40-minute scenario hard limit
Make caps every scenario at 40-45 minutes. The fix is architectural: split into webhook-handed-off children, checkpoint to a Data Store, voluntarily exit at 35:00.

TL;DR: Make caps a single scenario run at 40 minutes on Core, Pro, and Teams plans, and at an absolute 45-minute ceiling on Enterprise.
No setting extends it. The fix is to split the workload across multiple scenarios connected via webhook handoff: the parent queues batches, fires a child scenario per batch via webhook, then exits. Each child runs in its own fresh 40-minute window. The built-in "Run a scenario" module does not help - it is synchronous, so the parent's clock keeps running while it waits.
The other thing that kills long scenarios early: Make's 10,000-operations-per-execution cap. Even with time to spare, a scenario over 10,000 ops dies on queue overflow. The same pattern fixes both - chunk, checkpoint, hand off.
What do Make's 40 and 45 minute limits actually mean?
Make publishes the per-plan execution limit in the scenario execution flow help page. The numbers as of 2026:
| Plan | Max scenario runtime | What happens at the limit |
|---|---|---|
| Free | 5 minutes | Execution stops mid-flow, partial output. Operations consumed. |
| Core / Pro / Teams | 40 minutes | Same - hard kill at 40:00 wall-clock. |
| Enterprise | Up to 45 minutes (negotiable on enterprise SLAs only) | Same. |
"Hard kill" means at 40:00 the scenario stops, any in-flight module call is dropped, and downstream modules never run. If you were halfway through inserting 5,000 rows into Airtable, the first 2,300 are committed and the remaining 2,700 never happen. There is no rollback. This is the failure mode that destroys data integrity if you don't design around it.
Why doesn't "Run a scenario" extend the limit?
The first instinct most people have is to use Make's built-in "Run a scenario" module to call a child scenario from inside the parent. It looks like chaining; it isn't, in the way that helps here. The parent waits synchronously for the child to finish, and the parent's own 40-minute clock keeps ticking while it waits.
Parent scenario (clock starts at 0:00)
-> 30 minutes of work
-> Run a scenario [Child] # parent now at 30:00
Child scenario runs for 15 minutes
Child returns at parent-time 45:00
-> Parent continues... # KILLED, parent already at 40:00The child scenario does not get its own fresh 40-minute window from the parent's perspective. It gets whatever time is left on the parent's clock. If the parent is already 30 minutes in, the child has 10 minutes before the whole thing dies.
This is by design - "Run a scenario" exists for composing reusable subroutines, not extending wall-clock time. Use it for "factor out this 5-step block into something reusable," not "make my long-running ETL fit in the budget."
How do you fix the architecture with a webhook handoff between scenarios?
The pattern that actually works: the parent scenario fires a webhook trigger to a child scenario and exits. The child runs in its own fresh execution context, with its own 40-minute window. Webhook handoffs are asynchronous - the parent does not wait for the child.
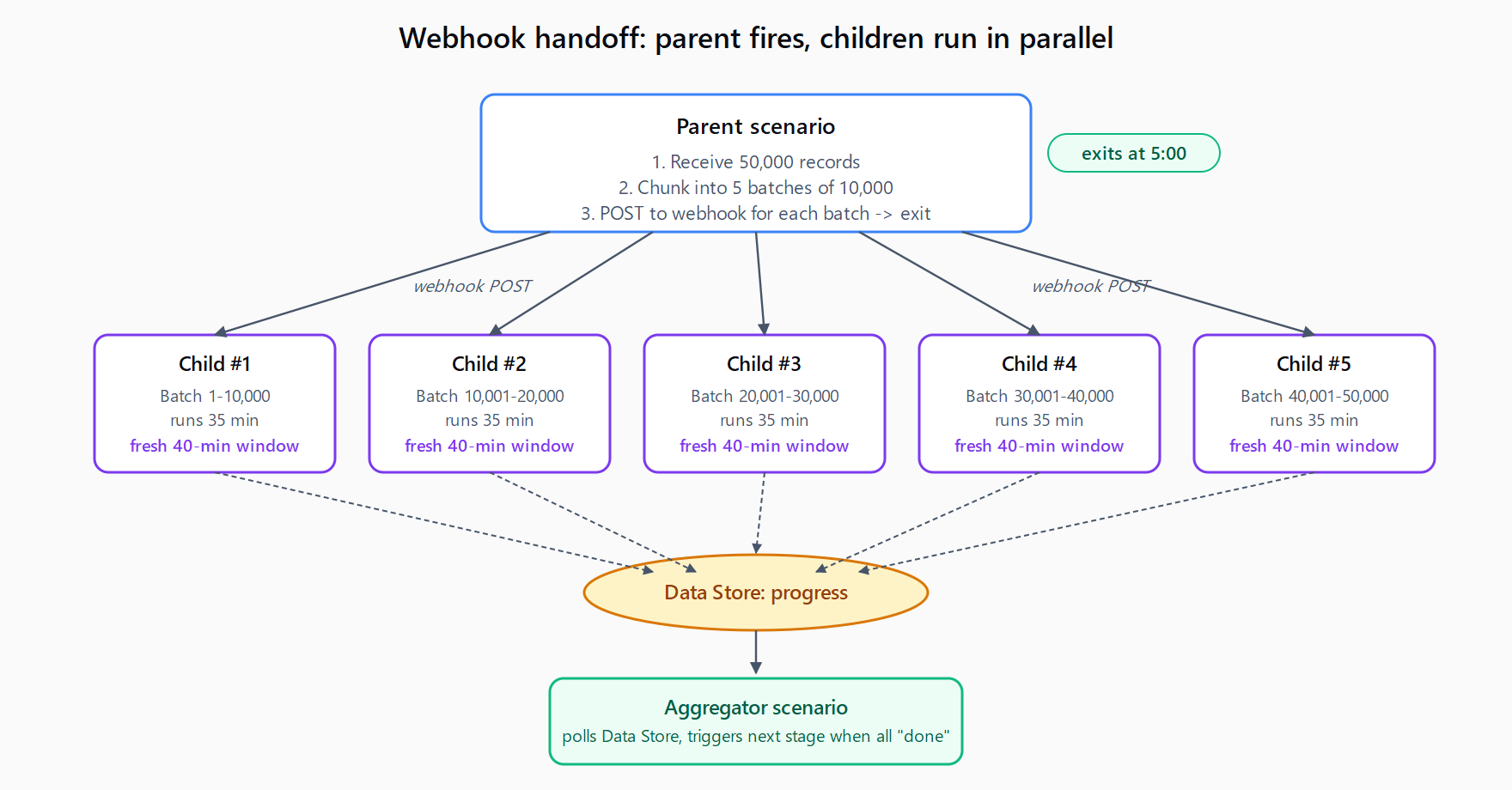
The implementation, step by step:
- Create the child scenario first. Trigger module = Webhooks → Custom webhook. Save the webhook URL.
- In the parent, add the chunking logic. Use an Iterator or array aggregator to split the input into batches of 1,000-2,500 records each. (Smaller batches = more child runs = better resilience to one batch failing.)
- For each batch, add an HTTP module to call the child's webhook. Method = POST, URL = the saved webhook, body = JSON payload with the batch and a sequence number.
- Set the parent to "Sequential" off and turn on "Allow storing of incomplete executions" off. The parent should fire the webhooks fast and exit. Children run in parallel - that is the point.
- In the child scenario, write completion to a Data Store row keyed by sequence number. An aggregator scenario can poll the Data Store and trigger the next stage when all batches show "done."
The parent scenario in this pattern usually finishes in under 5 minutes regardless of input size, because all it does is split-and-fire. The work happens in the children, each of which is bounded by its own 40-minute clock. To process a million records on Make, run 100 child scenarios of 10,000 records each.
How do you checkpoint and resume long runs on Data Store?
Webhook handoff fixes the architecture. It does not fix the case where a single batch genuinely cannot finish in 40 minutes - usually because the upstream API is slow and you are getting rate-limited or hitting per-module retries. For that, add a checkpoint pattern.
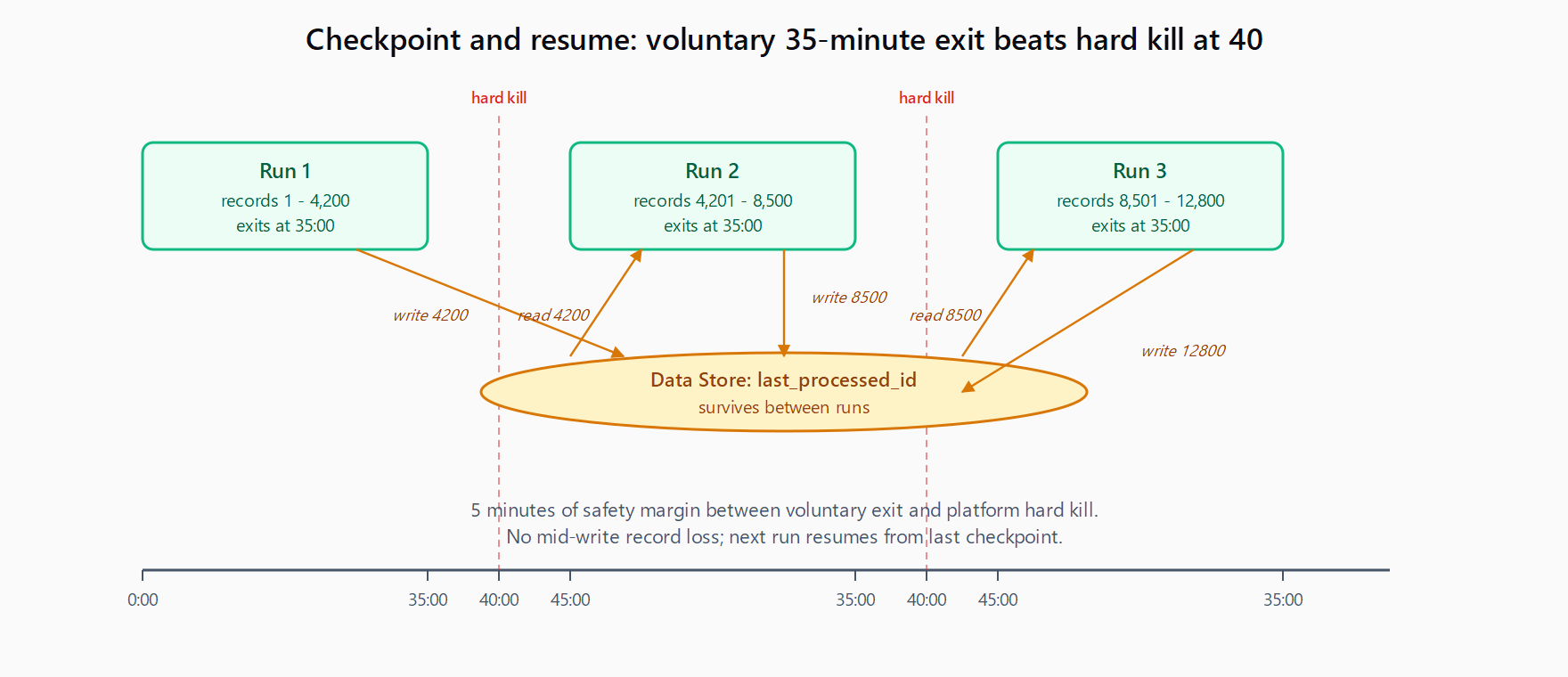
The pattern:
- Create a Data Store with one row per logical job. Columns:
job_id,last_processed_id,status. - At the start of every run, the scenario reads the row, gets
last_processed_id, and starts processing from there. - After each successful record, update
last_processed_idin the Data Store. On the same module call, not in a separate one - synchronous writes prevent losing progress on a hard kill. - Add a "time elapsed" check at the top of the loop. If the scenario has been running 35 minutes, exit cleanly. The next scheduled run picks up from
last_processed_id. - Set the scenario schedule to every 45 minutes. Each run drains 35 minutes' worth of work, exits gracefully, and the next run continues. A 4-hour ETL becomes 6 sequential 35-minute scenarios over the same wall clock.
The 35-minute exit is the load-bearing detail. Hard-killing at 40 minutes loses whatever record was mid-write. Voluntary exit at 35 minutes leaves a clean checkpoint. The same checkpoint pattern applies to long-running HTTP requests in n8n when you cannot avoid talking to a slow upstream API - the failure mode is different but the architectural answer is the same.
How do you keep batches under the 10,000 operations cap?
Make also caps a single execution at 10,000 operations regardless of time. An "operation" is roughly one module run per record - so a scenario that processes 5,000 records through 3 modules does 15,000 operations and dies on operation count, not time.
The symptom looks different from a timeout - the scenario fails with an "execution exceeded operations limit" error rather than the timeout-kill marker - but the fix is the same: chunk the input. If your scenario does N modules per record, the maximum batch size before you hit the operations cap is roughly 10000 / N. For a typical 4-module ETL, that means batches of 2,500 records.
This caps the practical batch size for the webhook handoff pattern at 1,000-2,500 records per child, even when 40 minutes would have been enough time. Don't chunk to fit time only; chunk to fit operations too.
When should you move off Make to a different platform?
If your job genuinely requires sustained execution past 45 minutes and can't be split (a single long-running model inference, a video render, a transaction-scoped DB migration), Make is the wrong tool. Self-hosted n8n removes the limit but you operate the infrastructure. AWS Step Functions handles long-running orchestration with state and retries - higher complexity floor, no execution ceiling. The 40-minute cap is the price of having someone else run the runtime; rarely worth fighting. This is the same trade-off that comes up with Make's MAXIMUM EXECUTION TIMEOUT error per-scenario: the fix is architectural, not configurational.
FAQ
What is the maximum runtime of a Make scenario?
40 minutes on Free, Core, Pro, and Teams plans. Up to 45 minutes on Enterprise. There is no setting to go beyond 45 minutes - the limit is platform-imposed and applies to every scenario regardless of plan tier within that band.
Can I increase the 40-minute scenario timeout in Make?
No. There is no toggle, setting, or paid add-on that extends a single scenario past its plan limit. The fix is architectural: split the workload across multiple scenarios connected by webhook handoff, where each child gets its own fresh 40-minute window.
Why does my scenario stop at 40 minutes even though I am on a paid plan?
40 minutes is the paid-plan limit on Core, Pro, and Teams. Only Enterprise plans negotiated through sales can run scenarios up to 45 minutes. The hard kill at 40:00 is a wall-clock cut-off - any in-flight module call is dropped and downstream modules never run. Design for it, not against it.
How do I split a long Make scenario into smaller ones?
Use webhook handoff: in the parent, chunk the input into batches and call a child scenario's webhook URL via an HTTP module for each batch. The child scenario triggers on the webhook and processes its batch in its own 40-minute window. The parent exits as soon as the webhooks are fired - it does not wait for the children.
Can the "Run a scenario" module bypass the timeout?
No. The "Run a scenario" module is synchronous - the parent waits for the child to finish, and the parent's 40-minute clock keeps running during the wait. The child does not get a fresh window from the parent's perspective. To get a fresh window, you need an asynchronous webhook handoff instead.
What is the difference between scenario timeout and module timeout in Make?
Scenario timeout is the wall-clock limit for the entire scenario run (40-45 minutes). Module timeout is the per-module call limit (default 40 seconds; configurable on some modules up to 300 seconds). A module timing out can cascade into scenario timeout if the module retries and the retries push total wall time past 40 minutes.
Hit a different error? Browse the Automation Error Index for a searchable catalog of Make errors, each with a verified fix.