13 signals AI assistants use to decide what to cite
ChatGPT and Perplexity don't pick sources randomly. Here are the 13 structural and off-site signals that determine whether your page gets cited.

TL;DR: AI assistants like ChatGPT and Perplexity select pages to cite based on 13 measurable signals - the highest-impact ones are a direct answer in the first 60 words, question-style headings, FAQ sections, and sourced statistics.
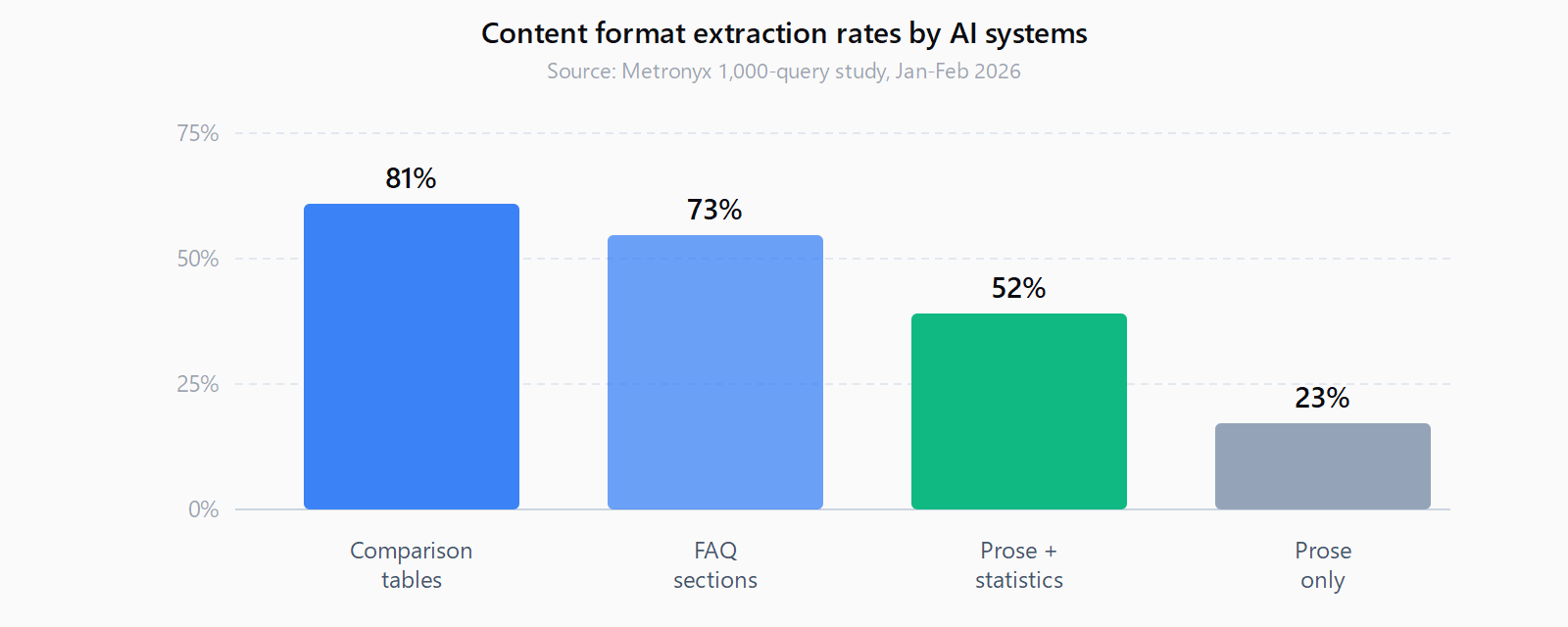
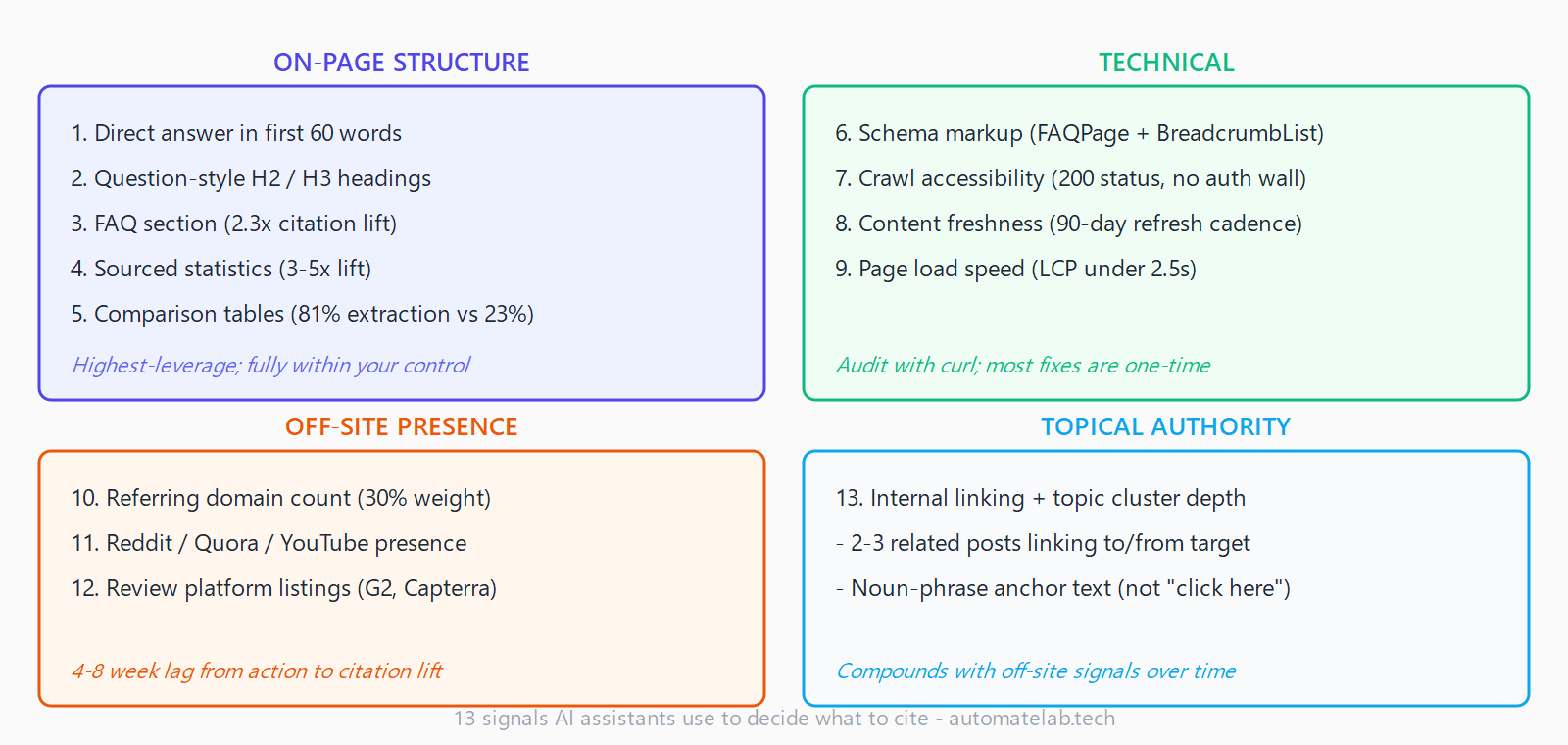
Most guides frame AI citation as a content quality problem. It is not. A technically sound page with a comparison table gets extracted at 81%; the same information in a prose block gets extracted at 23%. The gap is structural, not qualitative. Below are the 13 signals AI assistants score when deciding whether to cite a page, how to check each one, and how to fix it. These expand the eight dimensions that AI-citation eligibility auditing tools score - with five additional off-page and structural signals the standard audit misses.
How was this list built?
The 13 signals are drawn from three empirical sources: a 1,000-query ChatGPT citation study run across 10 categories in January-February 2026, ConvertMate's correlation analysis of referring-domain counts vs. citation frequency, and Frase's GEO research showing that 44.2% of all LLM citations come from the first 30% of a page's text. No invented statistics; every number below has a source linked inline.
Signal 1: Is there a direct answer in the first 60 words?
AI assistants extract from the top of a page first. Frase's research puts 44.2% of all LLM citations in a page's first 30% of text. The practical fix is an "answer capsule" - one to two sentences at the start of the page (and at the start of each major section) that contain the full claim without requiring the reader to scroll. Check it by reading your opening paragraph in isolation and asking whether it answers the query completely. If it sets context instead of giving the answer, rewrite.
Signal 2: Are the H2 and H3 headings question-shaped?
The Metronyx study found that 72% of ChatGPT-cited pages used question-style headings. Headings phrased as queries ("How do AI assistants select sources?" rather than "Source selection") map directly onto the user's prompt and make section extraction trivial for the retrieval step. Check: count how many of your H2s could be typed into a search box. Fix: rewrite declarative headings as interrogative ones. "Overview" becomes "How does X work?" "Common issues" becomes "What causes X to fail?"
Signal 3: Does the page have an FAQ section?
FAQ sections are cited at 2.3x the rate of pages without them, per the Metronyx study. The reason is mechanical: a question paired with a short paragraph answer is the highest-density extraction target AI systems have. FAQ blocks also drive FAQPage schema (Signal 9), so the structural and semantic signals compound. Check: does your page end with an H2 "FAQ" block containing H3 questions and paragraph answers? Fix: add three to six long-tail variants of your main query as Q&A pairs. Pull phrasing from Google's "People Also Ask" boxes for that query.
Signal 4: Does each section include sourced statistics?
Pages with sourced statistics are cited 3-5x more often, per the Metronyx study. Specific numbers with linked sources make a page's claims verifiable, which is exactly what AI assistants need to justify citing it. The Contently / ConvertMate analysis recommends at least 19 data points per page for maximum citation pull. Check: grep your page for `%`, `$`, `x more`, `x faster`. Fix: replace generic claims with sourced numbers. "Significantly faster" becomes "23% faster per the vendor's 2026 benchmark." Link the source on the specific noun phrase.
Signal 5: Does the page include comparison tables?
Comparison tables are extracted by AI systems at an 81% rate; prose expressing the same information is extracted at 23%. Tables are structured data the retrieval step can lift without ambiguity. Check: for any post that compares two or more options (tools, plans, approaches), look for a `` tag. Fix: convert the comparison from prose to a table. Minimum columns: option name, key differentiator, best for. Ghost renders plain HTML tables cleanly - no plugin needed.
Signal 6: Is FAQPage and BreadcrumbList schema present?
Structured data gives pages 3x more citations than paragraph-only content, per Frase's GEO research. FAQPage schema turns your FAQ block into machine-readable Q&A that feeds directly into AI systems' knowledge retrieval. BreadcrumbList schema signals content hierarchy. Check: curl your page and grep for `"@type": "FAQPage"`. Fix: add JSON-LD blocks to your page's `` or code injection field. Ghost's `codeinjection_head` field accepts raw script tags; a schema block for a 5-question FAQ takes under 30 lines of JSON.
Signal 7: Is the page accessible to AI crawlers?
If an AI crawler cannot fetch your URL, no other signal matters. Pages must return a clean 200 status code, load without authentication walls or login gates, and remain reachable by common crawler user agents (GPTBot, PerplexityBot, ClaudeBot, Google-Extended). Check: `curl -I https://yourdomain.com/slug/` should return `HTTP/1.1 200`. Check your `robots.txt` for `Disallow: /` or explicit blocks on the crawler names above. Fix: allow the AI crawlers in `robots.txt` and remove any interstitials on content pages.
Signal 8: Has the content been updated in the last 90 days?
Pages updated within 3 months are cited roughly 2x more often than pages with the same content but older timestamps, per the Metronyx study. ConvertMate's data is sharper: 76.4% of ChatGPT citations come from content updated within the last 30 days. The signal here is not rewriting - it is updating. Add a new data point, update a version number, or add a "Last updated: [date]" line visible in the page body. Check: look at your page's `published_at` and `updated_at` in Ghost admin. Fix: schedule a 90-day refresh cadence for your top 20 pages.
Signal 9: How fast does the page load on Core Web Vitals?
AI crawlers time out on slow pages the same way Googlebot does. A page that passes the extraction step but fails to load within the crawler's timeout window gets dropped from the candidate pool before any content signals are evaluated. Check: PageSpeed Insights on your page slug. Target LCP under 2.5 seconds. Fix: compress images (pngquant cuts PNG size 60-80% with no visible quality loss), serve assets from a CDN, and defer non-critical JavaScript.
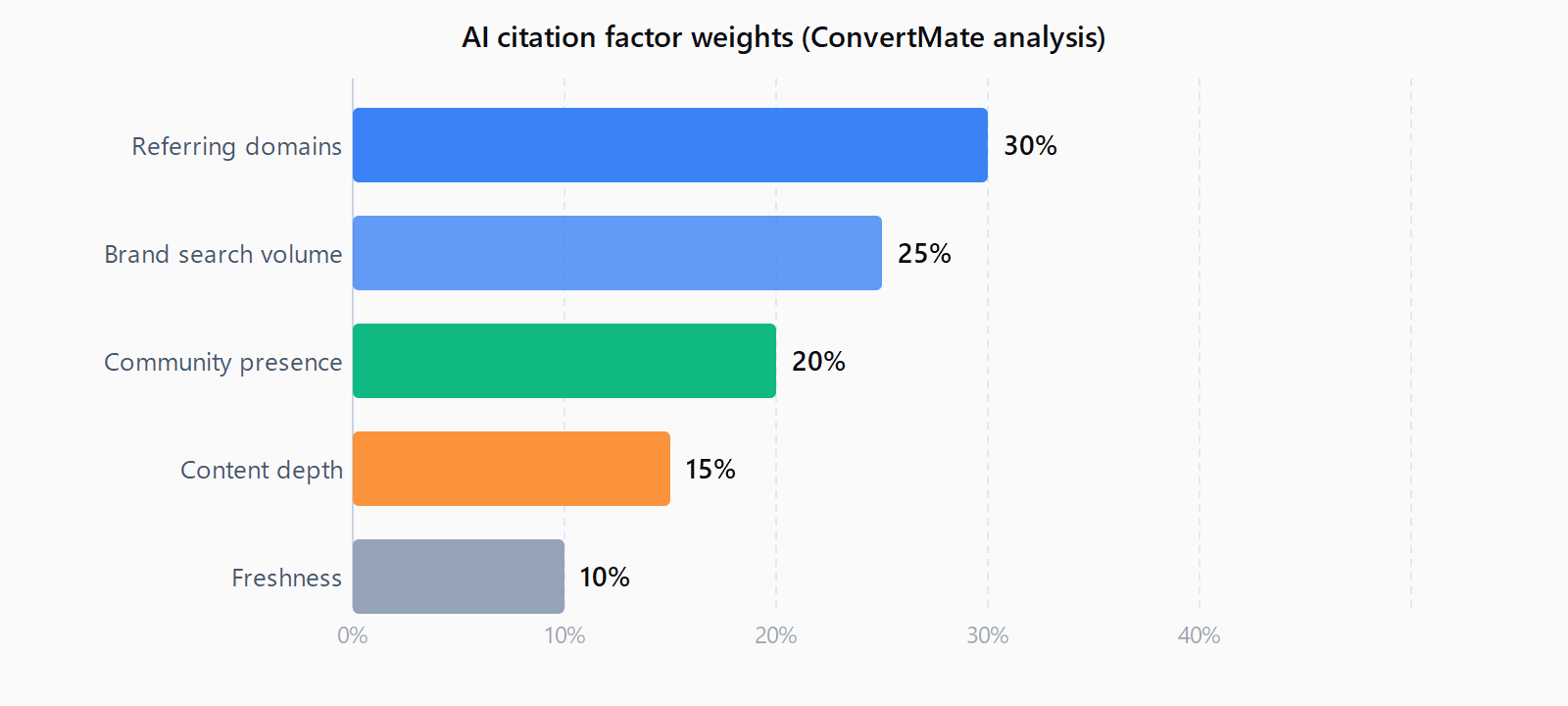
Signal 10: How many referring domains and brand mentions does the page have?
ConvertMate's citation factor analysis weights referring domains at 30% of the total citation equation - the single largest factor. Sites with 350,000+ referring domains averaged 8.4 ChatGPT citations; sites with 2,500 averaged 1.6-1.8. Brand mentions (not necessarily links) from authoritative domains compound this. Check: Ahrefs or Semrush for referring domain count. Fix: the standard link-building playbook applies - original research earns mentions, comparison page outreach places your page on lists AI already cites, and co-marketing with established brands transfers authority. This is a long-horizon signal; expect 4-8 weeks of lag from link acquisition to citation lift.
Signal 11: Is the brand present on Reddit, Quora, and YouTube?
AI systems over-index on community platforms. Reddit presence gives a 3.9x citation multiplier vs. minimal presence; Quora gives 4.1x. YouTube shows the strongest single correlation at 0.737 (Ahrefs' 2025 analysis). The mechanism: AI assistants use community discussion to verify and triangulate claims. A brand or page mentioned consistently across Reddit threads, Quora answers, and YouTube transcripts becomes higher-confidence source material. Check: search your brand or page name on Reddit and Quora. Fix: participate in relevant subreddits and Quora topics with genuine, source-linked answers. For YouTube, transcripts are the citation surface - not views.
Signal 12: Is the brand listed on G2, Capterra, and Trustpilot?
Domains listed on review platforms show 4.6-6.3 ChatGPT citations vs. 1.8 for unlisted domains. Review platforms function as third-party validators: AI systems use them to confirm a brand or product exists and has real users. Check: search your brand on G2, Capterra, and Trustpilot. Fix: claim listings and ensure the product description matches your page content. Consistency between your site's claims and review platform descriptions is the signal - not star ratings.
Signal 13: Does the site show strong internal linking and topical depth?
AI systems evaluate whether a page is part of a coherent topic cluster or a one-off post. Pages internally linked from multiple related posts on the same domain signal topical authority. The Model Context Protocol post on this site, for instance, links back to and from several n8n and AI-agent posts - that cluster structure is visible to crawlers and retrieval systems. Check: count how many of your other pages link to the page you want cited. Fix: build a cluster - two to three related posts that link to and from the target page on topical noun phrases. Internal links should use the noun phrase as anchor text, not "click here" or "read more."
How do you check all 13 signals on a single page?
The Ghost blog publishing workflow on this site runs the AI-SEO MCP's audit_page tool as part of the pre-publish pipeline. audit_page scores eight of the 13 signals above automatically (signals 1-4, 6-7, 8, 13) and returns a per-signal pass/fail with the fix instruction. The remaining five (5, 9, 10, 11, 12) require off-site data that the MCP does not have access to - check those manually using the "how to check" steps above. Run the audit on your highest-traffic pages first; a single structural fix on a page already ranking in the top 10 often produces citation results within 30-60 days.
FAQ
Does domain authority affect AI citations?
Yes - referring domain count is the single largest factor in ConvertMate's citation analysis at 30% of the total signal weight. However, on-page structural signals (signals 1-6) are entirely within a publisher's control and can produce citation gains independent of domain size. Small sites with strong structure do get cited; low-structure sites with high authority often do not.
Does schema markup directly cause AI citations?
Schema markup does not cause citations the way a direct link does. It makes your content easier for AI systems to parse and extract, which raises the probability of being included in a candidate pool. FAQPage schema is the most impactful type because it mirrors the Q&A shape AI assistants prefer for extraction. BreadcrumbList and Article schema add context about the page's place in the site hierarchy.
How often should I update content to stay citation-eligible?
ConvertMate's data shows 76.4% of ChatGPT citations come from content updated within 30 days, but the Metronyx study found a meaningful advantage at the 90-day mark. A 90-day refresh cadence is the practical minimum - update data points, check version numbers, and add a visible "last updated" date in the body. Pages in fast-moving spaces (AI, SaaS pricing) need monthly attention.
Do AI assistants cite brand-new websites?
Rarely, and the lag is real. Citation gains from off-site work (signals 10-12) typically lag by 4-8 weeks per ConvertMate. For new domains, on-page signals (1-6) are the fastest path to initial citations because they do not depend on accumulated authority. Getting indexed on one review platform and having a few community mentions is achievable in the first 90 days.
How is getting cited by AI different from ranking on Google?
Traditional search ranking weighs hundreds of signals over months. AI citation is faster and more structural: a single well-formatted FAQ block or a comparison table can make a page extractable immediately. The off-site signals overlap (domain authority, links) but the on-page signals diverge - Google has never explicitly rewarded question-style headings or FAQPage schema the way AI retrieval systems do. Treat AI citation as a separate optimization track that runs in parallel with, not instead of, standard SEO.
Does page length affect AI citation probability?
Page length affects citation probability indirectly. Pages under 600 words are often too thin to satisfy the query context AI systems need. Pages over 3,000 words dilute the answer density - the highest-signal content gets buried past the 30% threshold where most citations originate. The 1,200-2,500 word range covers most informational queries and keeps answer density high enough for reliable extraction.
To get all 13 of these signals implemented on your site, see the AI SEO service — schema, llms.txt, AI-crawler access, FAQPage structure, entity links, and brand-citation tracking in a fixed-scope engagement.