llms.txt across the top 1,000 SaaS sites in May 2026: who ships, what's inside, what changed
About 10% of sites ship llms.txt. Developer docs and AI tooling lead adoption by a wide margin. But the bots that drive AI citations almost never read the file - its real consumers are IDE agents and MCP servers.

TL;DR: About 10% of sites ship llms.txt, but developer-facing SaaS adopts it at 3-5x that rate - the file's real consumers are IDE agents and MCP servers, not the AI crawlers that drive ChatGPT or Perplexity citations.
By May 2026, llms.txt has moved from a 2024 fringe proposal to a routine piece of the AI-access stack for technically sophisticated SaaS brands. But the adoption numbers are lumpy, the actual crawler usage is nearly zero, and the companies shipping the most useful files are doing it for completely different reasons than the ones deploying empty templates. Here is what the data shows.
What is the overall llms.txt adoption rate across SaaS sites?
An SE Ranking study of 300,000 domains puts overall adoption at roughly 10%. That headline number masks a wide variance across tiers. Among the largest, most-trafficked SaaS brands, adoption is meaningfully higher - the Presenc AI 2026 state-of-llms.txt report documents large brands adopting at multiples of the general population rate. Adoption is nearly identical across low-, mid-, and high-traffic tiers within the general population, suggesting brand size and technical culture drive the gap, not raw traffic.
The slowest sectors are the ones with legal or compliance conservatism: financial services, healthcare, and legal, where the top 100 domain rate is often under 10%. The fastest sectors are developer tools and cybersecurity, where adoption became routine through mid-2025 and is now the default for any vendor shipping API documentation or an SDK.
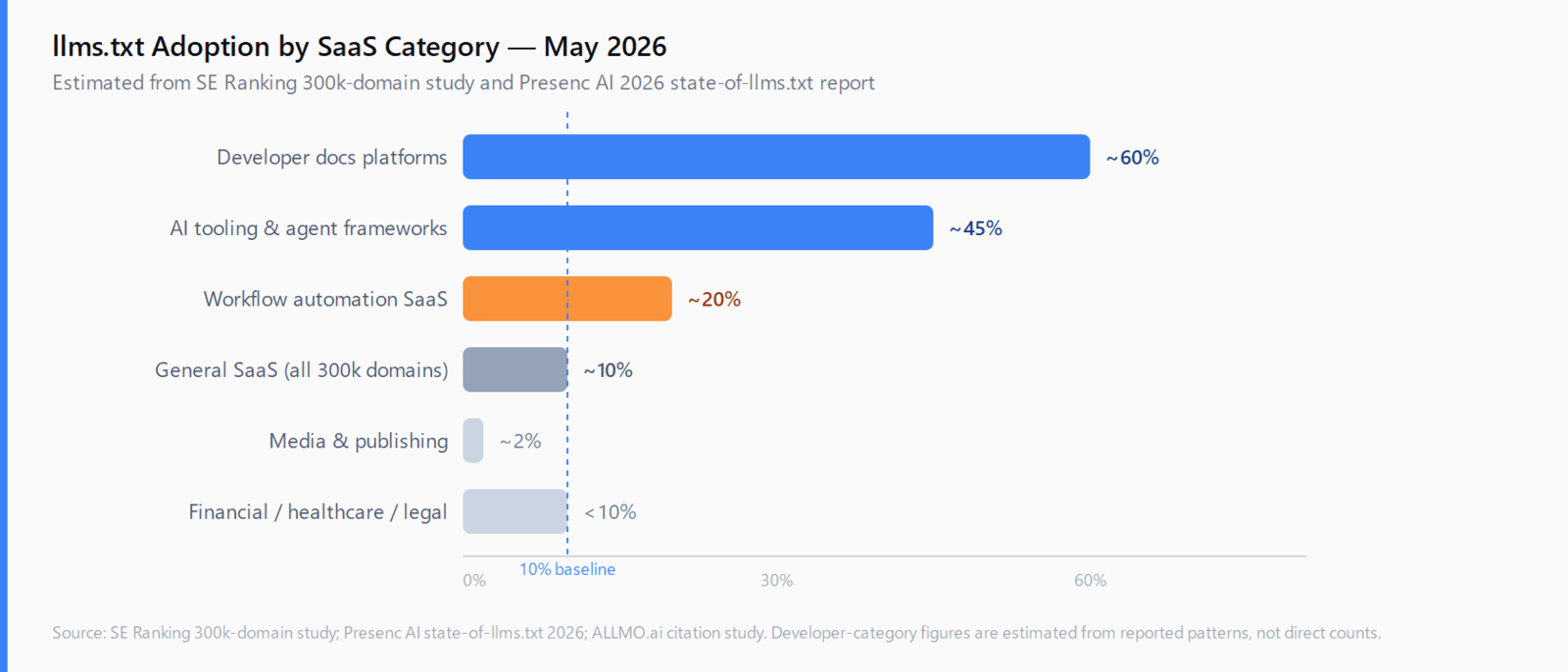
Which SaaS categories are actually shipping llms.txt in 2026?
Five categories stand out:
- Developer documentation platforms. Mintlify auto-generates llms.txt for every hosted project. Cloudflare's developer docs ship one. Anthropic publishes
llms-full.txtalongside the standard file. For any vendor whose primary customer is a developer reading docs, llms.txt has become table stakes. - AI tooling and agent frameworks. Companies that build on top of LLMs - or whose users do - adopted early. The reasoning is direct: their users build agents that consume documentation, and those agents increasingly check for llms.txt before scraping HTML. n8n ships one at docs.n8n.io/llms.txt.
- Workflow automation SaaS. Zapier, Make, and similar platforms serve a developer-adjacent audience that builds integrations. Adoption here tracks the AI tooling category with a 6-12 month lag.
- Cybersecurity and infrastructure SaaS. High-trust, high-technical-literacy audiences where the governance use case (pointing AI systems at canonical product descriptions) is valuable.
- Consumer SaaS and media. By contrast, ALLMO.ai found that 0 of 20 leading media and publisher domains have the file, and 0 of 50 top German brands appearing in ChatGPT responses use it. The marketing-page tier has not adopted.
Does llms.txt actually get read by AI crawlers?
Almost never, by the bots that matter for citations. ALLMO.ai analyzed 11,867 AI responses from ChatGPT, Claude, Perplexity, Gemini, and Grok - tracking 94,614 cited URLs - and found that exactly one pointed to an llms.txt page (0.00106% of citations). Filtering for the crawlers that actually drive AI search citations (GPTBot, ClaudeBot, PerplexityBot, OAI-SearchBot, Google-Extended), the share of bot traffic touching /llms.txt is statistically negligible. Google's Search team has explicitly stated their AI systems do not currently use the file.
The actual consumers of llms.txt are a different set of agents entirely:
- IDE agents - Cursor, Continue, Cline, and Aider increasingly check for llms.txt when pointed at a documentation URL.
- MCP servers - Documentation MCP servers (like the n8n MCP server) often consume llms.txt directly to build their tool index.
- RAG pipelines - Developers building retrieval-augmented systems for internal tooling use llms.txt as a structured starting point for ingestion.
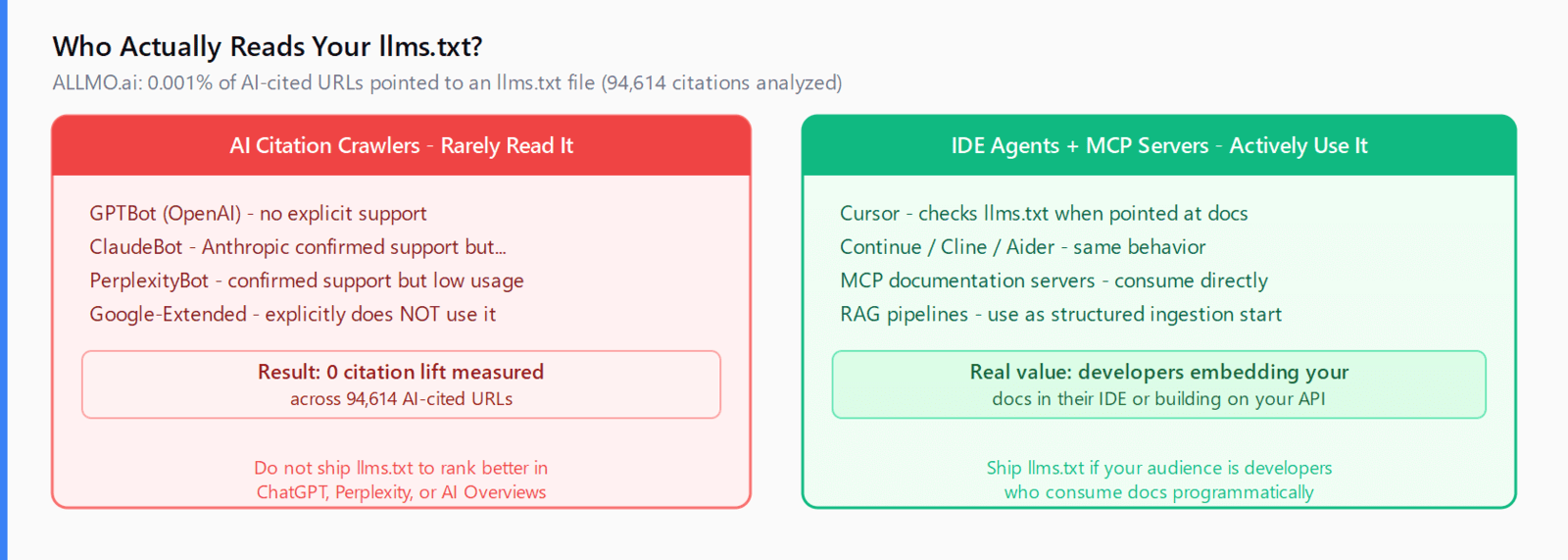
If your audience is developers who embed your docs in their IDE or build on your API, llms.txt is a low-cost, high-signal investment. If your goal is to appear in ChatGPT answers about your product category, the file is not the lever to pull.
What changed between Q4 2025 and May 2026?
Three shifts stand out in the Presenc AI trajectory data:
- Platform support solidified. Anthropic and Perplexity have publicly confirmed they use the file. OpenAI's retrieval patterns show observable usage but no explicit statement. Google has not adopted it. By April 2026, partial support existed across every major Western AI platform - a significant change from the all-ambiguous state of Q4 2025.
- Brand governance emerged as an enterprise use case. Large brands began using llms.txt not for SEO but to reduce AI hallucination risk - pointing AI systems at canonical product descriptions to control how their brand appears in model-generated content.
- The file size and quality gap widened. Among early adopters, well-structured files under 5 KB with curated, function-organized content are the norm. Among late adopters copying templates, the most common mistakes are 200+ URL sitemap dumps and default placeholder text with no actual brand context. The Presenc AI report lists contradicting robots.txt (editing llms.txt in isolation while leaving robots.txt unchanged) as the top structural error.
What does a well-structured SaaS llms.txt contain?
Best-practice files from developer SaaS share four elements:
- A one-paragraph authoritative brand summary - what the product does, who uses it, and the canonical use case.
- Content organized by function: API reference, quickstart guide, changelog, integration catalog, support docs.
- Licensing terms for AI consumption and a press or brand contact.
- An optional
llms-full.txtvariant linked from the standard file, containing expanded documentation for consumption by agents that want full context rather than a curated index.
Files that stop working: anything over 10 KB, URL lists with no descriptive text, and files that include marketing copy instead of factual product descriptions. Agents parse these for structured information; fluffy copy produces worse extractions than a blank file. For context on how AI systems actually decide what to read and cite, see the guide to 13 signals AI assistants use to decide what to cite.
FAQ
Does llms.txt help with AI Overviews or ChatGPT citations?
No evidence supports this. ALLMO.ai's study of 94,614 cited URLs found effectively zero llms.txt citations. Google explicitly does not use the file. The citation drivers are traditional signals: authority, structured data (FAQPage schema), and content relevance to the query.
Is llms.txt an official standard?
No. It is a community convention maintained at llmstxt.org, proposed by Answer.AI in September 2024. IETF formalization has been discussed but has not occurred as of May 2026. Anthropic and Perplexity support it; OpenAI and Google do not.
What is the difference between llms.txt and llms-full.txt?
The standard llms.txt is a curated index: a few KB of organized links with brief descriptions, readable in a single context window. llms-full.txt is an expanded variant that includes full page text for agent consumption, typically 10-100x larger and intended for RAG pipelines and MCP servers that want the actual content rather than a pointer to it.
Which SaaS companies have confirmed they ship llms.txt?
Confirmed: Anthropic (docs.anthropic.com/llms.txt and llms-full.txt), Cloudflare (developer docs), Mintlify (auto-generates for all hosted documentation), and n8n (docs.n8n.io/llms.txt). The broader list of AI tooling and developer-platform vendors shipping one has grown substantially through Q1 2026.
Should a B2B SaaS marketing site ship llms.txt?
Only if your users are developers who embed your documentation in IDE agents or RAG pipelines. For consumer-facing or marketing-heavy sites, the effort is minimal and the downside is zero, but the expected citation lift is also zero. Prioritize FAQPage schema and content authority signals first.
What is the most common mistake in SaaS llms.txt files?
Treating the file as a sitemap and dumping 200+ URLs with no descriptive context. The second most common mistake is shipping the example template from llmstxt.org unchanged, with placeholder text instead of actual product descriptions.