AI search invisibility: 7 reasons your site isn't cited (and how to fix each)
Most 'not cited by ChatGPT' diagnoses oversell the robots.txt fix. The seven real blockers cluster into access, extraction, and authority - here's the diagnostic for each.

TL;DR: Most "fix your robots.txt" advice for AI search is oversold (BuzzStream's March 2026 analysis of 4 million citations found 88.2% of GPTBot-blocking sites still get cited), so the seven real blockers cluster into access (bot blocks, JS-only rendering, walled gardens), extraction (buried answers, missing schema), and authority (weak entity signals, no earned-media co-occurrence), and most "not cited" sites lose on extraction or authority rather than access.
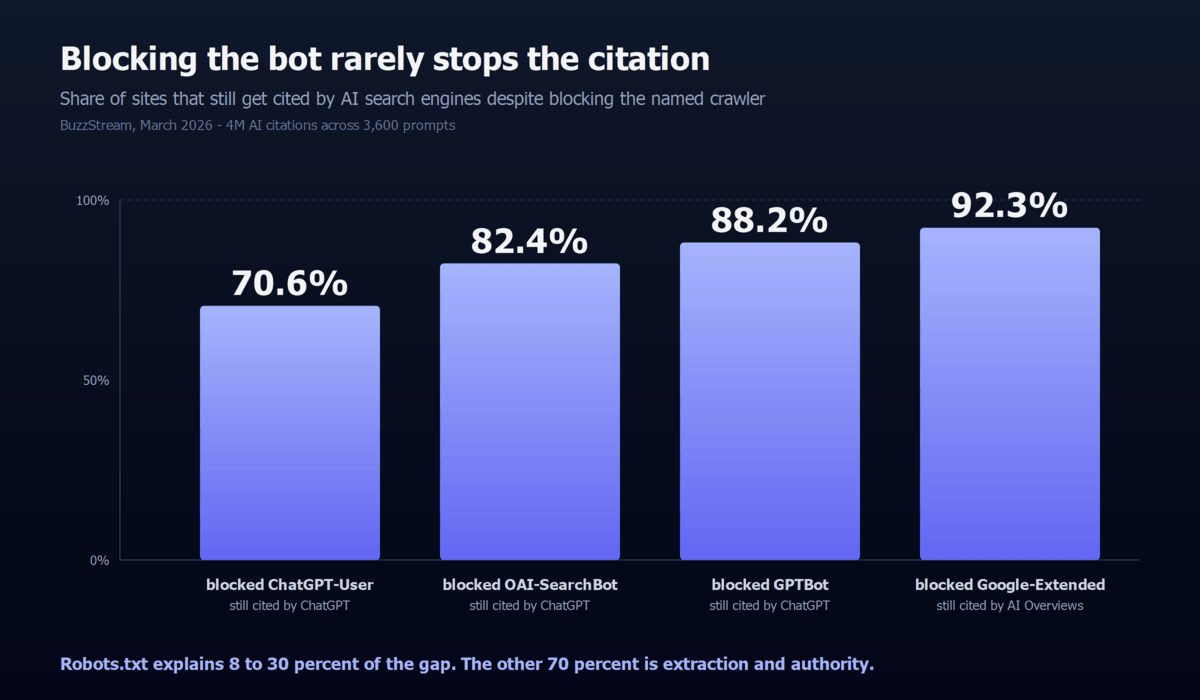
You typed your brand into ChatGPT or Perplexity, asked the question your content answers, and watched it cite three competitors instead. The fix you'll see recommended most often is to open up robots.txt, and you should. But it explains less of the gap than the SEO blogosphere implies. BuzzStream's March 2026 analysis of 4 million citations across 3,600 prompts found that 88.2% of sites blocking GPTBot still showed up in ChatGPT citations, and 92.3% of sites blocking Google-Extended still showed up in Google AI Overviews. The retrieval pipeline routes around the block more often than not.
So if robots.txt isn't doing the work, what is? Below are the seven blockers we see when we audit sites that rank organically but go silent in AI answers, grouped by how often they're actually the cause. Tier 1 (access) matters but explains the minority. Tier 2 (extraction) and Tier 3 (authority) are where most invisibility lives in 2026.

Tier 1: What access blockers stop AI assistants from reading your site?
1. The retrieval bot is blocked in robots.txt
Symptom: Curl your page with the retrieval-bot user-agent and get a 403, or your robots.txt has a blanket Disallow: / under User-agent: * with no per-bot exception.
Diagnostic: Three commands, swap your domain in:
curl -A "OAI-SearchBot/1.0" -I https://yourdomain.com/your-page
curl -A "Claude-SearchBot/1.0" -I https://yourdomain.com/your-page
curl -A "PerplexityBot/1.0" -I https://yourdomain.com/your-pageAny non-200 response, or a robots.txt that resolves to a block for those agents, is a hard miss.
Fix: Allow the three retrieval bots explicitly. Training bots (GPTBot, ClaudeBot, CCBot) are a separate decision. Block those if you don't want your content in model training, but keep the retrieval bots open:
User-agent: OAI-SearchBot
Allow: /
User-agent: Claude-SearchBot
Allow: /
User-agent: PerplexityBot
Allow: /
User-agent: GPTBot
Disallow: /
User-agent: ClaudeBot
Disallow: /The walkthrough lives in our 2026 GEO and AEO technical checklist.
2. The page is JS-only rendered
Symptom: View source on your page and the answer-bearing copy isn't in the HTML, it loads after a React/Vue/Next.js hydration step.
Diagnostic: curl https://yourdomain.com/page | grep -i "your answer phrase". If the phrase isn't in the response body, retrieval bots don't see it either. They don't execute JavaScript on first fetch, and they bail before hydration completes.
Fix: Server-render the answer-bearing portion of the page. Next.js with getServerSideProps or React Server Components, Astro static, plain HTML; anything that puts the prose in the initial response. Client-side interactivity around the prose is fine.
3. The answer is behind a paywall or login gate
Symptom: Your highest-quality content requires an email signup, account creation, or paid subscription to read.
Diagnostic: Open the page in a fresh incognito window. If you can't read it, the bot can't either.
Fix: Either ungate a clean answer-shaped excerpt of 200-400 words above the gate, or accept that this content won't drive AI citations and lean on the ungated content for visibility. Soft paywalls that show full content to search bots but gate humans are now treated as cloaking by both Google and the retrieval bots, so don't try it.
Tier 2: What extraction blockers stop AI assistants from quoting your content?
This is where most "ranks fine but never cited" sites actually lose. The bot can reach the page. It just can't pull a clean answer chunk out of it.
4. The answer is buried under context paragraphs
Symptom: Your post leads with three paragraphs of preamble before stating what the reader came to find out.
Diagnostic: Ask a colleague to read the first 80 words of any blog post and tell you the answer to its title. If they can't, neither can the retrieval pipeline.
Fix: Lead each H2 with the question phrased the way a user would type it, then put a 60-80 word direct answer immediately under it. Per Search Engine Land's reporting on AI Overviews, "a section under a specific heading should completely answer the question posed in that heading, without requiring surrounding context." Add depth and nuance after the answer, not before it.
5. There's no FAQPage or Article schema
Symptom: Google's Rich Results test on your URL shows zero structured data, or the schema you have is WebPage only.
Diagnostic: Paste your URL into Google's Rich Results test. If you don't see Article, FAQPage, or HowTo in the detected types, that's the blocker.
Fix: Ship two JSON-LD blocks per post:
Article(orBlogPosting) with author, datePublished, dateModified, headline, imageFAQPagewith 4-6 verbatim question-answer pairs that match the PAA boxes Google surfaces for your target query
Pixelmojo's 2026 benchmark found pages with FAQPage schema were 3.2x more likely to be cited by retrieval-based engines than pages with no structured data. The schema gives the bot a pre-extracted answer surface; without it, you're hoping it scrapes correctly.
Tier 3: What authority blockers stop AI assistants from trusting your site?
The bot can reach you. It can extract an answer. It still doesn't cite you because it doesn't believe the answer comes from somewhere worth quoting.
6. Weak entity signals (no Organization sameAs)
Symptom: Search your brand name in Google. If there's no Knowledge Panel and no Wikipedia entry, the retrieval engines can't tie your domain to a confirmed entity. Your content reads as "some blog said X" instead of "Brand X said X."
Diagnostic: Check whether your homepage ships an Organization JSON-LD block with a sameAs array linking to your verified profiles. Crunchbase, LinkedIn, GitHub, Wikidata if you have it, even a podcast feed counts.
Fix: Add this to every page (or at least the homepage and About page):
{
"@context": "https://schema.org",
"@type": "Organization",
"name": "Your Brand",
"url": "https://yourdomain.com",
"sameAs": [
"https://www.linkedin.com/company/your-brand",
"https://github.com/your-brand",
"https://www.crunchbase.com/organization/your-brand",
"https://www.wikidata.org/wiki/Q12345"
]
}Perplexity weights entity-graph signals heavily. Pages with a clean sameAs chain tend to be cited above thinly-defined competitor domains for the same query.
7. No earned-media co-occurrence
Symptom: You're cited by Perplexity (which crawls in real time) but invisible in ChatGPT (which leans on parametric knowledge baked in during training).
Diagnostic: Per AuthorityTech's analysis of 680 million citations, only 11% of domains cited by ChatGPT are also cited by Perplexity. If your asymmetry runs in the Perplexity-only direction, the issue is parametric authority. ChatGPT cites brands that appear in Wikipedia (7.8% of its citations), Reddit (37% of social citations), LinkedIn (36% of social citations), and editorial outlets, none of which are your own domain.
Fix: The lever is third-party mentions, not on-site optimization. Get yourself referenced on Reddit threads in your space, pitch comment quotes to editorial outlets, claim a Crunchbase profile, and if you're large enough, push for a Wikipedia entry. The 2026 GEO playbook is half technical and half PR.
How do you test all seven blockers in 20 minutes?
- Curl your page with
OAI-SearchBot,Claude-SearchBot,PerplexityBot. Expect 200 OK on each. - Curl without a user-agent and grep for your answer phrase. If absent, you're JS-only.
- Open the page in incognito. If you can't read it, neither can the bot.
- Read the first 80 words. If they don't answer the title, restructure.
- Run Google's Rich Results test. Look for
ArticleandFAQPage. - View your homepage source. Search for
"sameAs"in the JSON-LD. - Search your brand in Perplexity and ChatGPT side by side. Asymmetry means parametric-knowledge gap.
If you want to automate this across a sitemap on a schedule, we built the AI-SEO MCP for exactly that. It runs the bot-user-agent fetches and the schema audit and reports the per-page failure mode. The structural reasoning behind why these particular seven matter is in our companion piece on the 13 signals AI assistants use to decide what to cite.
FAQ
Why isn't my site showing up in ChatGPT?
Run the seven-step test above. The most common failure mode in 2026 is a buried answer paragraph plus missing FAQPage schema (extraction blockers), not a robots.txt block. Sites that rank organically and still don't show up in ChatGPT are almost always losing on extraction or authority, not access.
Does blocking GPTBot actually stop citations?
Mostly no. BuzzStream's March 2026 analysis of 4 million citations found 88.2% of GPTBot-blocking sites still appeared in ChatGPT citations. Blocking GPTBot opts you out of training, not out of being cited. The retrieval pipeline can pull from Common Crawl archives, SERP extracts, or third-party mentions that quote you.
How do I test which AI bots can reach my site?
Curl with each bot's user-agent and check the status code: curl -A "OAI-SearchBot/1.0" -I https://yoursite.com/page. Repeat for Claude-SearchBot, PerplexityBot, GPTBot, ClaudeBot. A 200 means the bot can fetch; a 403 or 401 means your stack is blocking somewhere (robots.txt, WAF, or Cloudflare bot management).
How long does it take for AI engines to pick up a new page?
Perplexity indexes within hours to a few days because its retrieval crawl runs continuously. ChatGPT's behavior depends on whether the page is reachable via OAI-SearchBot (real-time, similar to Perplexity) or only via training data (months, tied to the next model refresh). Claude sits in between. Publishing a sitemap and submitting it to Google still helps because SERP extraction is one of the retrieval routes.
What does it mean if I'm cited by Perplexity but not ChatGPT?
It means your retrieval surface is fine but your parametric-knowledge footprint is thin. Perplexity is live-crawling and seeing your page; ChatGPT is leaning on its training corpus and isn't finding your brand strongly associated with the query topic. Fix that with earned-media mentions and entity signals (sameAs links to Wikidata, Crunchbase, LinkedIn), not on-page changes.
Does Claude cite small sites?
Yes. Claude has the highest brand-owned citation share among major AI search engines (9.1% per AuthorityTech's overlap analysis) and the smallest domain-authority bias. If you've gotten the access and extraction tiers right, Claude is usually the first AI engine to start citing a new domain. ChatGPT comes last because of its training-cycle lag.
I run audits for clients. Can I get a templated version of this checklist?
Yes, our AI SEO service runs all seven checks across a full sitemap, returns the per-page failure mode, and sets the robots.txt and schema fixes for you. The MCP version is open-source if you'd rather wire it into your own audit pipeline.