How to get cited by ChatGPT, Perplexity, and Claude in 2026
Per-bot robots.txt rules, answer-extractable page structure, and JSON-LD schema - the three layers that actually move ChatGPT, Perplexity, and Claude citations in 2026.

TL;DR: Allow OAI-SearchBot, Claude-SearchBot, and PerplexityBot in robots.txt, block GPTBot training, lead each page with an H2 question plus an 80-word answer, ship FAQPage and Article JSON-LD, and skip llms.txt.
A November 2025 SERanking study of 300,000 domains found llms.txt produced no measurable lift in AI citations, yet most 2026 GEO checklists still tell you to ship it first. The signals that actually move ChatGPT, Perplexity, and Claude citations are older and less glamorous: per-bot crawler rules, answer-extractable page structure, and JSON-LD schema. Here is the full technical checklist, in the order we run it on automatelab.tech.
What do GEO, AEO, and AI SEO actually mean?
Three acronyms, one job. GEO (Generative Engine Optimization) is content tuning for ChatGPT, Claude, Perplexity, Gemini, and Mistral - the engines that synthesize answers from web pages. AEO (Answer Engine Optimization) is the older sibling that targets Google AI Overviews, featured snippets, and voice assistants. AI SEO is the umbrella term most marketers use for both, plus the schema and crawler-access work that feeds them.
The work overlaps enough that we treat it as one pipeline. Only 11% of domains are cited by both ChatGPT and Perplexity today, so the goal is not "rank for AI" - it is "get cited by enough different engines that you survive any single algorithm change."
Step 1: How do you split your robots.txt by bot purpose?
The biggest 2026 change is that the major AI vendors now run separate crawlers for training versus live retrieval. If you blanket-block AI bots, you also block the bots that drive citation traffic. If you blanket-allow them, you ship your archive into the next training run for free.
Use this starter template at /robots.txt:
# Allow retrieval crawlers (drive citation traffic)
User-agent: OAI-SearchBot
Allow: /
User-agent: Claude-SearchBot
Allow: /
User-agent: PerplexityBot
Allow: /
# Opt out of generative training (Google and Apple use tokens, not crawlers)
User-agent: Google-Extended
Disallow: /
User-agent: Applebot-Extended
Disallow: /
# Block training crawlers
User-agent: GPTBot
Disallow: /
User-agent: ClaudeBot
Disallow: /
User-agent: CCBot
Disallow: /A few details most guides miss:
Google-ExtendedandApplebot-Extendedare not crawlers. They are opt-out tokens. Blocking them does not affect Google Search ranking or Siri suggestions, only Gemini and Apple Intelligence training.Claude-User,ChatGPT-User, andPerplexity-Userare user-triggered fetchers - they fire when a human asks the assistant to "open this URL." Anthropic and OpenAI respect robots.txt for these; Google'sGoogle-Agentignores it by stated policy.Bytespider(ByteDance) and the xAI Grok crawler spoof browser user-agents and ignore robots.txt. They need server-side blocking, not robots.txt entries.

The full bot landscape changes every quarter. Our AI SEO service ships a monitored robots.txt that we update whenever a vendor adds or splits a user-agent.
Step 2: How do you restructure pages for answer extraction?
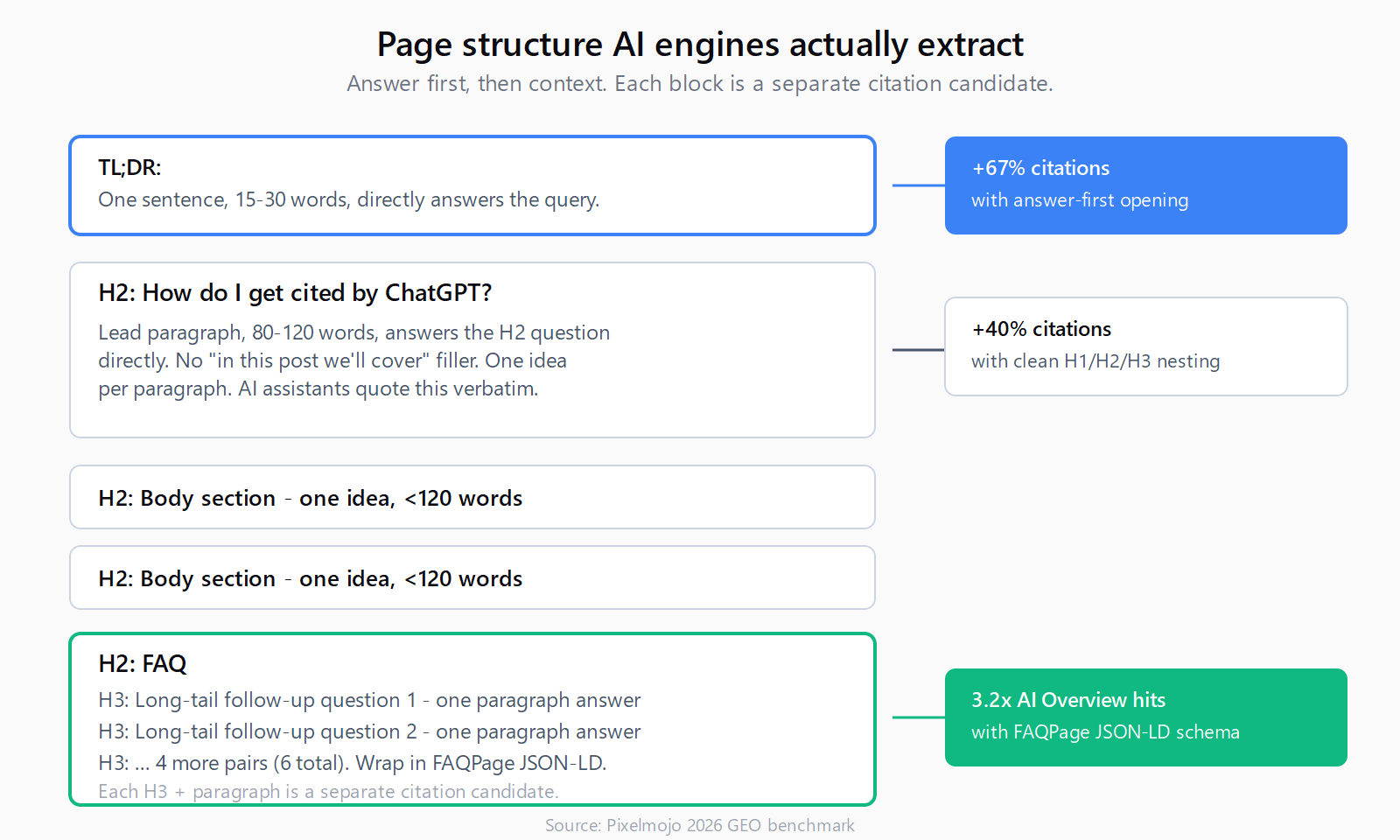
AI engines do not read your page - they extract spans. Three changes raise extraction rate the most:
- Lead with the answer. Pages with answer-first opening paragraphs are cited 67% more often than pages that bury the answer below context, per Pixelmojo's 2026 GEO benchmark. The TL;DR pattern at the top of this post is the same pattern AI assistants reward.
- Use H2 as the user's question. "How to get cited by ChatGPT" works; "Citation Strategy" does not. Pages with clean H1/H2/H3 nesting are cited 40% more often than pages with flat or skipped levels.
- Cap paragraphs at 120 words. One idea per paragraph. AI assistants quote paragraphs verbatim; long ones get truncated and skipped.
The other thing AI engines love is a dedicated FAQ block. Move your six most likely follow-up questions into an <h2>FAQ</h2> at the bottom with <h3> per question. Pixelmojo's 2026 GEO benchmark reports pages with FAQPage schema are 3.2x more likely to appear in Google AI Overviews.
Step 3: Which four schema types should you ship?
JSON-LD is the cheapest citation lever. Add it once in your template, get the lift forever. The four types that actually move citations:
Articlewithauthor(named person, not "Editorial team"),datePublished, anddateModified. AI assistants weight recency heavily.FAQPagewrapping your bottom-of-page FAQ. Independent benchmarks put this at the largest single citation lift among schema types.HowTofor any post with a numbered procedure. ChatGPT'sOAI-SearchBotindexes the step text into a separate structure.OrganizationwithsameAspointing to your Wikipedia entry, Crunchbase, LinkedIn, and GitHub org. This is how engines reconcile you to a known entity - the precondition for being cited by name instead of as an anonymous URL.
Validate with Google's Rich Results Test and Schema.org's validator before deploying. A broken JSON-LD block is worse than none.
Step 4: Should you ship llms.txt?
The llms.txt spec proposes a Markdown index at /llms.txt that points AI agents at your canonical content. It is a clean idea. It does not currently help with citations.
The November 2025 SERanking study analyzed 300,000 domains: roughly 10% had an llms.txt, adoption was identical across traffic tiers, and the file produced zero measurable improvement in AI citation frequency. Server-log analysis from sites that shipped one shows GPTBot occasionally fetches it, while ClaudeBot, Google-Extended, and PerplexityBot effectively do not.
Where it does help: IDE agents like Cursor, Continue, and Cline read llms.txt to scope their context. If you sell to developers, ship one - but treat it as a developer-experience tool, not a citation tool. Don't let it displace work on robots.txt and schema.
Step 5: How do you measure citation share instead of rankings?
Google rankings tell you nothing about AI citations. You need a different instrument. We track three signals:
- Direct citations. Manually query 10 target keywords on ChatGPT, Perplexity, and Claude each week. Log which queries cite you. Free, takes 15 minutes.
- Referral traffic by AI source. Filter Google Analytics or Plausible for referrers matching
chatgpt.com,perplexity.ai,claude.ai,gemini.google.com. The numbers are small but trending. - Server-log bot hits. Watch retrieval crawler activity on new posts. If
OAI-SearchBothasn't fetched a post within 14 days, your sitemap or internal linking is broken.
For automation, our AI-SEO MCP wraps these checks into 13 tools an agent can run unattended.
Why don't most pages get cited by AI assistants?
If you have done everything above and citations are still flat, the cause is almost always that AI engines don't recognize you as an entity worth quoting. That is upstream work - building topical depth in one cluster, getting picked up by Wikipedia or Crunchbase, earning citations from already-cited domains. We mapped the full upstream stack in 13 signals AI assistants use to decide what to cite; this checklist is the technical floor underneath it.
If you want the full audit, schema retrofit, and ongoing monitoring done for you, that's our AI SEO service - nine modules from crawler audit to programmatic AEO, with a fixed-price scope and a four-week handover.
FAQ
What's the difference between GEO, AEO, and AI SEO?
GEO targets generative engines (ChatGPT, Claude, Perplexity, Gemini, Mistral). AEO targets answer engines (Google AI Overviews, voice assistants, featured snippets). AI SEO is the umbrella term covering both, plus the schema, robots.txt, and entity work that feeds them. Most agencies use the three terms interchangeably.
Should I block GPTBot in robots.txt?
Block GPTBot (the training crawler) and allow OAI-SearchBot (the live-retrieval crawler that drives ChatGPT Search citations). The two are separate user-agents. Blocking both means no citation traffic from OpenAI; allowing both means OpenAI uses your content to train future models.
Does llms.txt help me get cited by ChatGPT?
No, based on current data. The November 2025 SERanking study of 300,000 domains found no measurable citation lift from llms.txt. GPTBot occasionally fetches it; ClaudeBot, PerplexityBot, and Google-Extended effectively don't. Ship one if you serve developer-tool users (Cursor, Continue, and Cline read it), but don't expect ranking impact.
Which JSON-LD schema types help AI citations the most?
FAQPage gives the largest lift in our test set (3.2x more AI Overview appearances). Article with a named author and dateModified is essential for recency. HowTo helps for any numbered procedure. Organization with sameAs links is the entity-reconciliation signal that lets AI engines cite you by name.
How long does it take to start getting cited by Perplexity vs. ChatGPT?
Perplexity indexes in 2 to 4 weeks because it uses real-time search. ChatGPT runs on Bing's index and takes 6 to 12 weeks. Google AI Overviews lift in 2 to 4 weeks once the underlying organic ranking holds. None of these are guaranteed - they assume the page is already structured for extraction and the domain has prior citations.
How can I track which AI assistants are citing my site?
Three layers: (1) manually query 10 target prompts weekly on ChatGPT, Perplexity, and Claude; (2) filter analytics for AI-source referrers; (3) watch server logs for OAI-SearchBot, Claude-SearchBot, and PerplexityBot hits on new posts. The AI-SEO MCP wraps these into one agent-runnable workflow.