LlamaIndex vs LangChain: which framework for RAG and agents?
LlamaIndex or LangChain? The right answer in 2026 is usually both -- LlamaIndex as the retrieval layer, LangGraph as the orchestration layer. Here is how to decide.

TL;DR: LlamaIndex is the retrieval layer for document Q&A and private-data RAG; LangChain/LangGraph is the orchestration layer for stateful multi-step agents -- and most 2026 production stacks run both together.
The question "LlamaIndex or LangChain?" sends most developers down a comparison rabbit hole. Both are Python frameworks for building LLM applications. Both handle RAG. Both support agents. But they start from opposite assumptions, and picking the wrong one as your foundation adds friction that compounds as the codebase grows.
What is LlamaIndex?
LlamaIndex (llama-index-core 0.14.22, May 2026) is a data framework designed around one idea: make it easier to connect private or proprietary data to an LLM. The core abstraction flows in one direction -- documents in, indexed representation out, natural-language query in, synthesized answer out.
The framework's strongest feature is its retrieval stack. Hierarchical chunking splits documents into parent and child chunks. The AutoMergingRetriever embeds the small child chunks for similarity search, then checks whether the retrieved children share a parent chunk above a configurable threshold -- if they do, it returns the whole parent instead of the fragments. The result is more coherent context passages without tuning the chunk size by trial and error.
For PDF-heavy workflows, LlamaParse handles table extraction and structured document parsing that generic loaders miss.
In 2026 LlamaIndex released a stable Workflows API that replaces the older monolithic QueryEngine assembly. Workflows are async, event-driven pipelines where each step receives typed events and emits typed events. llama-deploy runs those workflows as production services with a control plane and per-workflow message queues. The shift matters because it makes multi-step RAG pipelines composable without monkey-patching the underlying engine.
What is LangChain?
LangChain is an orchestration framework for composing LLM applications. The canonical expression is LCEL -- LangChain Expression Language -- which uses a pipe operator to declare linear chains: prompt | model | parser. Every component exposes a uniform invoke() method, so swapping a model or adding a retriever step is one line.
For agents, LangChain provides create_agent: a minimal, configurable harness that pairs a model with a list of tools. As of October 2025, create_react_agent delegates its execution loop to LangGraph's engine internally. This matters for the comparison -- the two frameworks are converging toward a layered stack, not diverging as competitors.
LangGraph is the low-level runtime for stateful agents. It models execution as a cyclic StateGraph: nodes are Python functions, edges define routing, and the graph can loop back on itself. State is checkpointed to SQLite, Postgres, or Redis after every node, so a long-running agent can survive a crash and resume. The interrupt_before hook places a human approval gate on any node without rewriting the agent. The full LangChain vs LangGraph decision is covered in a separate guide; the short version is that LCEL handles linear pipelines, LangGraph handles everything cyclic.
LangSmith is the observability layer: trace every tool call, inspect model inputs and outputs, replay failed runs. LangChain also ships 600+ provider integrations -- model connectors, vector stores, document loaders, memory backends -- which is roughly ten times what LlamaIndex covers out of the box.
How do the two frameworks compare for RAG?
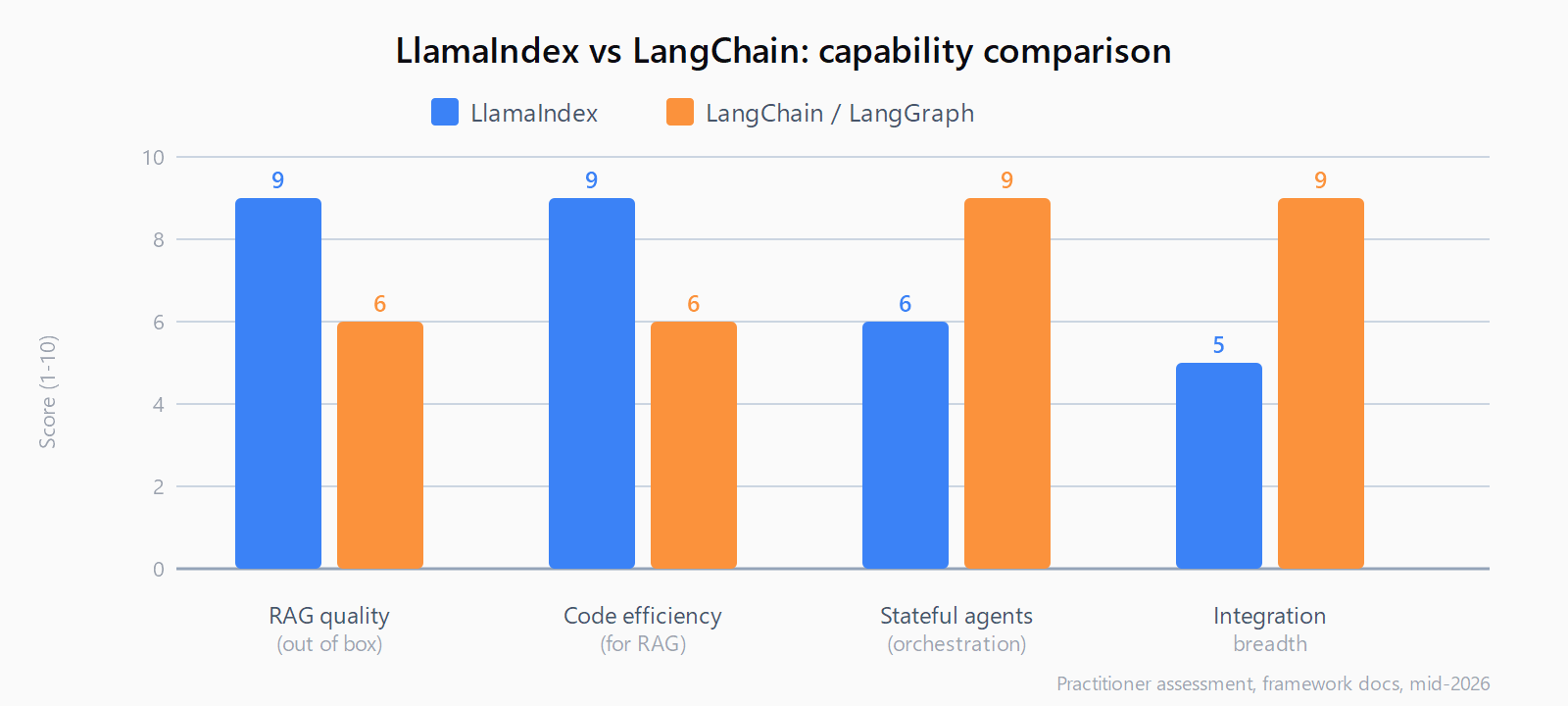
LlamaIndex reaches production RAG faster. Benchmarks show LlamaIndex achieving higher retrieval accuracy on document Q&A; tasks than an equivalent LangChain pipeline, and the code is typically 30-40% shorter for the same retrieval logic. The hierarchical chunking and auto-merging retriever deliver better results at default settings; LangChain achieves comparable accuracy but requires more custom tuning of chunk sizes, overlap, and re-ranking strategy.
LangChain's RAG implementation is more modular: split, embed, index, retrieve, rerank, format, generate are separate components you wire together with LCEL. That modularity pays off when the retrieval pipeline mixes sources -- video, images, APIs, structured databases alongside text -- or when the retrieval is one piece of a larger workflow that also handles tool calls and memory. If the whole application is retrieval and retrieval only, LlamaIndex's opinionated defaults get you there faster.
| Dimension | LlamaIndex | LangChain |
|---|---|---|
| RAG code volume | 30-40% less for equivalent pipeline | More verbose, more modular |
| Out-of-box retrieval quality | Higher at defaults | Requires tuning |
| Chunking strategy | Hierarchical + auto-merging built in | Custom, component-based |
| PDF and table extraction | LlamaParse included | External library needed |
| Media types supported | PDFs, structured data, text | Video, APIs, images, text |
| Integration breadth | RAG-focused | 600+ providers |
How do the two frameworks compare for agents?
LlamaIndex agents are data-first: the agent wraps one or more QueryEngines as tools, then reasons over them with a ReAct loop. The question the agent answers is almost always "what does my data say about X?" The Workflows API expands this to multi-step pipelines, but the data layer remains central.
LangGraph agents are orchestration-first. The agent has a state object, a set of tools, and a cyclic graph that defines routing logic between them. It is designed for workflows where the agent might loop ten times, call five different APIs, pause for human review, and resume after an approval -- patterns where LlamaIndex's event-driven model works but requires more scaffolding.
For pure document-aware agents (a research assistant that retrieves from a knowledge base and answers questions), LlamaIndex alone is sufficient. For agents that span retrieval plus external APIs plus stateful memory plus human checkpoints, LangGraph is the right orchestration layer -- and you can feed it a LlamaIndex QueryEngine as one of its tools.
When should you use LlamaIndex and LangChain together?
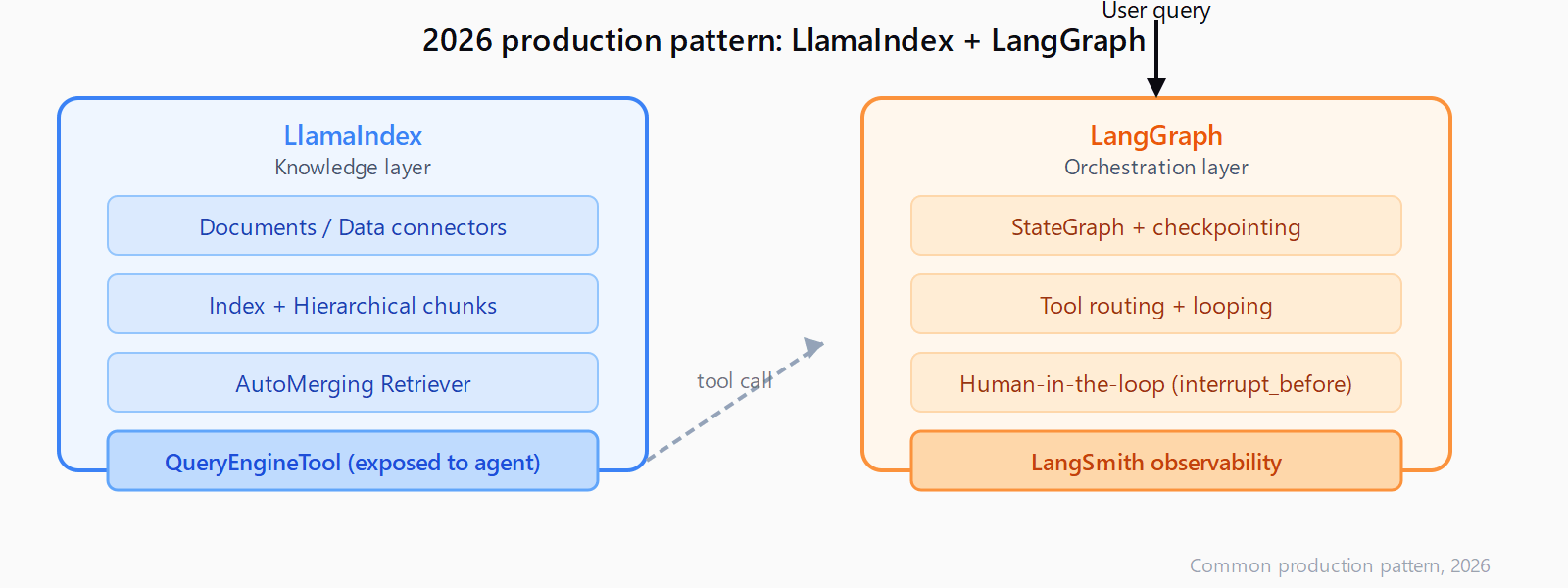
Most 2026 production stacks use both. The pattern: LlamaIndex handles the knowledge layer (index, chunk, retrieve, synthesize from documents), and LangGraph handles the orchestration layer (tool routing, state management, looping, human-in-the-loop). LlamaIndex exposes a QueryEngineTool that wraps any QueryEngine with a name and description; LangGraph treats it as one tool in its harness alongside API calls, database queries, and other agents.
That combination also fits naturally with agentic workflows that layer LLM reasoning on top of deterministic process automation. The retrieval stack stays inside LlamaIndex; the process routing stays inside LangGraph; neither framework needs to replicate the other's strength.
Choosing one or the other as the sole framework is usually a sign that the application is early-stage. A prototype that only retrieves from a PDF corpus probably does not need LangGraph. A stateless tool-calling agent that never touches a document corpus probably does not need LlamaIndex. The question becomes binary only at the prototype stage; production apps tend to need both layers.
FAQ
What is the main difference between LlamaIndex and LangChain?
LlamaIndex is a retrieval framework: it specializes in indexing documents, chunking them for embedding, and synthesizing answers from retrieved context. LangChain is an orchestration framework: it composes LLM calls, tools, memory, and routing logic into pipelines and agents. They solve different layers of the same problem.
Which is better for RAG: LlamaIndex or LangChain?
LlamaIndex reaches production RAG with less code and higher out-of-box retrieval accuracy. LangChain achieves comparable results with more tuning and is a better fit when RAG is one component of a larger multi-source pipeline. If retrieval quality is the whole product, start with LlamaIndex.
Can LlamaIndex and LangChain be used together?
Yes -- and most production stacks do exactly that. Wrap a LlamaIndex QueryEngine in a QueryEngineTool and register it as a tool in a LangGraph agent. LlamaIndex handles retrieval; LangGraph handles orchestration, state, and routing.
Is LangChain still relevant in 2026?
Yes. Since October 2025, LangChain's agent loop runs on LangGraph's engine internally, so the two are converging rather than competing. LCEL plus LangGraph plus LangSmith is the canonical production stack for stateful agents. LangChain's 600+ integrations and observability tooling (LangSmith) remain its primary advantages.
What LangChain errors should I watch for?
The most common runtime issue with complex agents is hitting iteration limit errors when a ReAct loop doesn't converge. Migrating to LangGraph's StateGraph removes the iteration cap and gives explicit control over when the agent stops.
What is LlamaIndex's Workflows API?
The Workflows API, stabilized in 2026, replaces the older pattern of assembling QueryEngine objects with typed event-driven pipelines. Each step in the workflow receives events and emits events; llama-deploy runs those workflows as persistent services. It makes multi-step RAG applications easier to debug and extend without rewriting the retrieval layer.